What is inference engineering? Deepdive
What is inference engineering? DeepdiveMany engineers use inference daily, but inference engineering is a bit obscure – and an area rich with interesting challenges. Philip Kiely, author of the new book, “Inference Engineering,” explainsTwo years ago, we learned about how LLMs work at a high level from the ChatGPT team, and today, almost all software engineers use large language models (LLMs) in our day-to-day work. The most visible part of using an LLM is inference; when an existing model takes an input (prompt) and generates an output, one token at a time. So, with AI models and AI agents everywhere across the tech industry in 2026, that means so is inference. And now, inference engineering is becoming more widespread, too, as open LLM models grow more capable. This is because with closed models, inference engineering is done only by the AI engineers who build the model, whose number might add up to a few thousand globally. In contrast, with the open models which tech companies are adopting, it’s possible to tweak them to perform better at inference. For example, Cursor built its new Composer 2.0 model on top of the open Kimi 2.5 model, and successfully used plenty of inference engineering approaches to make it even faster. So, based on this industry-wide prevalence and the related need for superior technical performance, it’s worth understanding a bit about what inference engineering actually is, and some interesting approaches worth knowing about, as a software engineer. For some answers, I turned to Philip Kiely, a software engineer who has been working for four years at the inference startup, Baseten. With his hard-earned experience, Philip has written an excellent, in-depth book about precisely this topic, “Inference Engineering.”
In today’s issue, we cover:
This deepdive uses a few abbreviations and concepts that are everyday lingo for inference engineers, but maybe are not for those less versed in the domain:
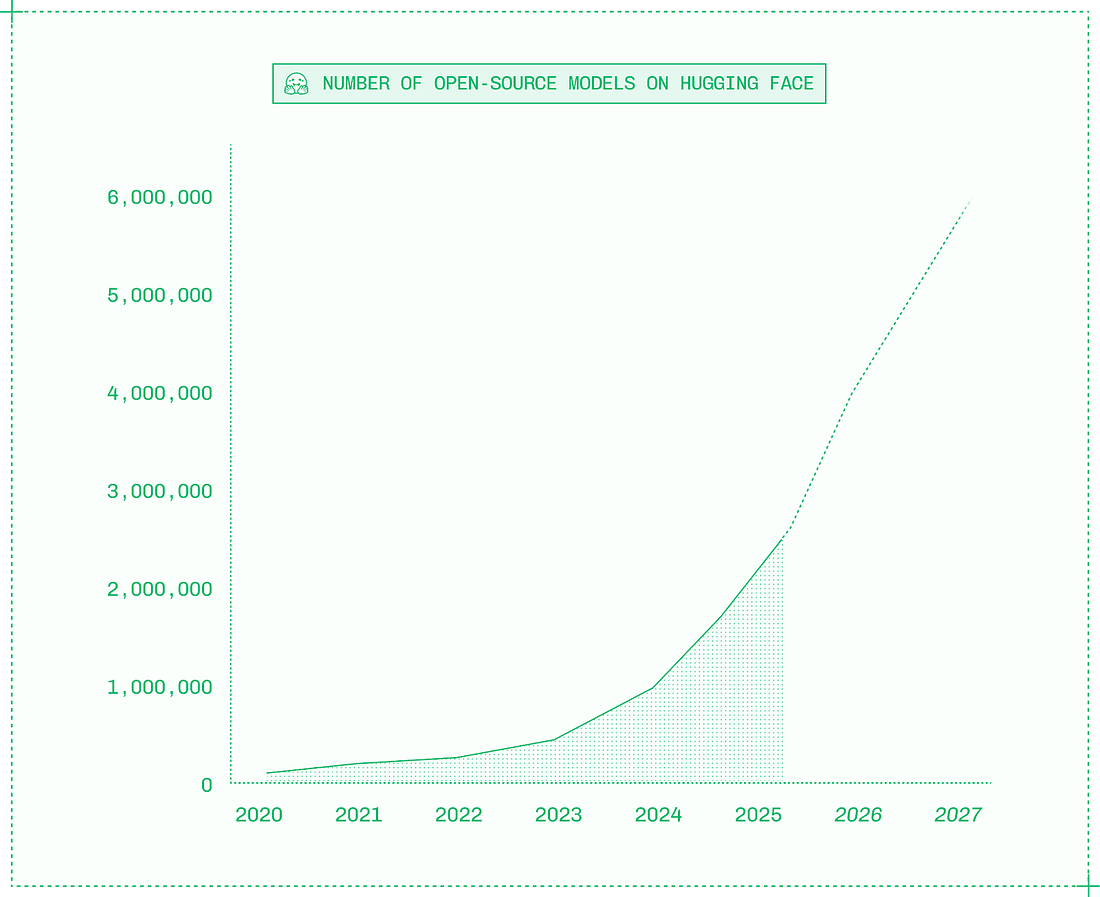
Below is an introduction to inference adapted from Philip’s book, “Inference Engineering,” which is free to download as an e-book. Physical copies are currently sold out, but Philip is printing more as fast as possible. My usual disclaimer: as with all my recommendations, I was not paid to mention this book, and no links in this article are affiliates. See my ethics statement for more. With that, it’s over to Philip: 1. Setting the stage: why is inference so important?Inference is the most valuable category in the AI industry, but inference engineering, on the other hand, is still in its infancy. In their work, inference engineers work across the stack from CUDA to Kubernetes in pursuit of faster, less expensive, and more reliable serving of generative AI models in production. When ChatGPT launched in late 2022, there were perhaps a few hundred inference engineers in the world, and they didn’t call themselves that. These specialists mostly worked at frontier labs like OpenAI, Midjourney, and Anthropic, or at big tech companies like Google and NVIDIA. Back then, it looked like this might be the way of the AI industry: that training generative AI models would be so hard and expensive that only a handful of companies would develop closed models and thereby require inference engineering for production serving. In that alternate future, the rest of the world would be mere consumers of AI via APIs, renting intelligence a token at a time. Three years later, it turns out that training generative AI models is indeed both hard and expensive – but it’s not so hard and expensive to be limited to a handful of players. Instead, a proliferation of open models – more than two million and counting on Hugging Face (the “GitHub for AI”) – means that today every engineer can now deploy their own intelligence to power AI products. Research labs around the world, from OpenAI and NVIDIA Nemotron in America, to Mistral AI and Black Forest Labs in Europe, to Alibaba Qwen, DeepSeek AI, Z AI, and Moonshot AI in China, regularly release open models of all modalities.
Despite closed models getting smarter and cheaper, the movement into open models is accelerating, which differ by the availability of their weights:
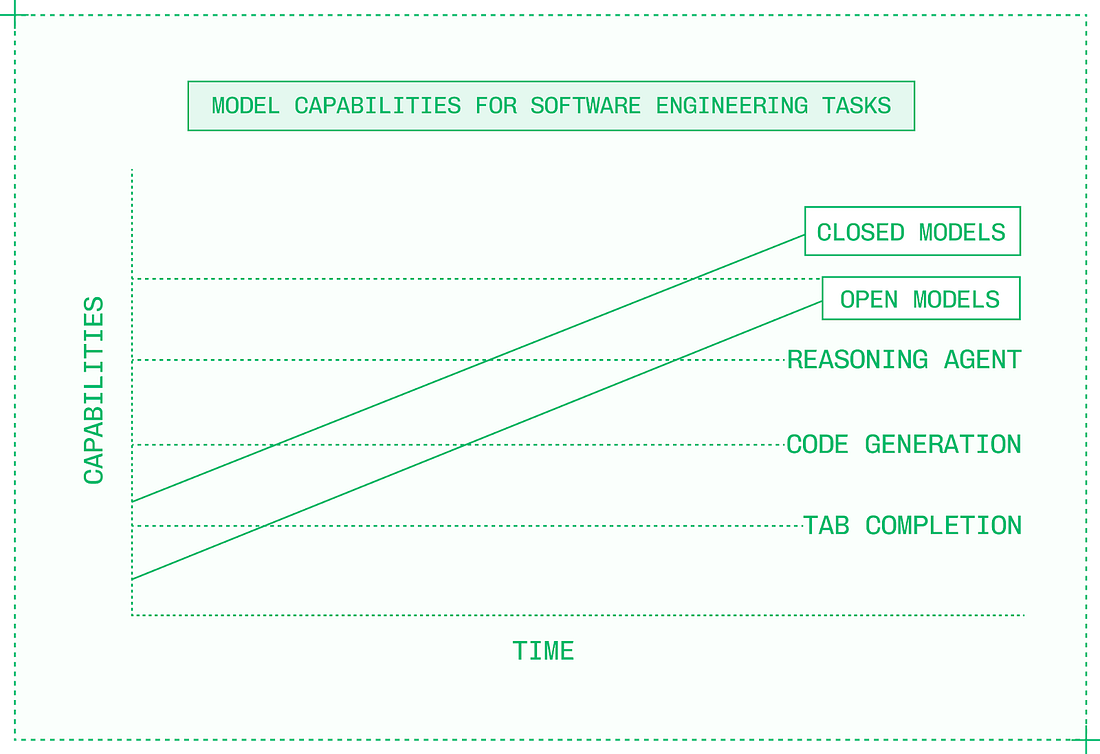
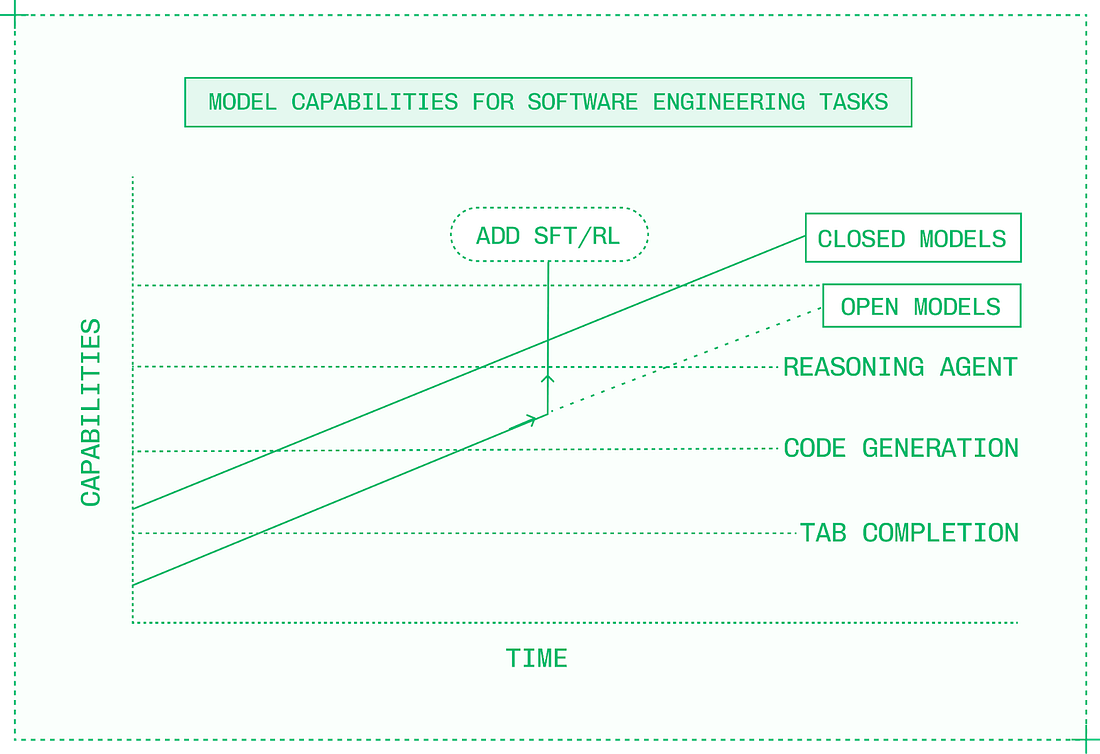
Before December 2024, there was a meaningful gap in intelligence between closed and open models, but when DeepSeek V3 and R1 were released, that gap disappeared. Note from Gergely: we previously covered how DeepSeek’s release rocked the AI industry. Today, new closed models are matched by open models within months if not weeks, and occasionally, open models like Kimi K2 Thinking even exceed closed models’ capabilities for brief periods. Despite the fact that open models are constantly chasing closed models on benchmarks, they nonetheless change the equation for AI product builders. And as both types improve, closed and open models cross capability thresholds.
In 2022, it was impossible to build the kinds of AI-native products that define the industry today. But over time, closed models got smarter and new categories like customer service voice agents and AI-powered IDEs became possible. The early models were slow, expensive, and unreliable, but the capabilities were there and AI engineers began building companies around them. As open models crossed the same capability thresholds, these folks began using them to replace closed models. Many also began fine-tuning open models to cross capability thresholds faster, and even exceed closed model quality in their specific product and domain.
Switching to open models means the opportunity to use inference engineering to make the models powering AI products better in new ways:
So, whereas three years ago it looked like inference engineering was a niche field, the fact is that today, every company aiming to build truly differentiated and competitive AI products needs an inference strategy. AI-native startups like Cursor, Clay, Gamma, and Mercor are redefining hypergrowth by building products that rely on open and in-house models. Leading digital native companies like Notion and Superhuman succeed by deeply integrating AI capabilities into their category-defining products. Elsewhere, a new generation of blended research and engineering teams – World Labs, Writer, Mirage, and dozens more – are building businesses by training and productizing their own foundation models. Adoption is even strong in enterprise and regulated industries, which historically were slow to adopt new technologies. Companies like OpenEvidence, Abridge, and Ambience are making generative AI ubiquitous in healthcare, while at the world’s largest companies, AI initiatives are moving past the pilot stage into massive user adoption. Market-wide demand for inference means that everyone from developers to executives has the opportunity to learn inference engineering and use it to advance their career and business. I’ve been incredibly fortunate to have a front-row seat in the fastest-moving market in history over the last four years at Baseten, where we power mission-critical inference for the best AI products, including every company listed in the previous paragraphs. The good news is that you are early. There are still relatively few professionals working on inference, and newcomers can become experts quickly. Also, the potential and impact of inference is becoming ever clearer, but the domain is still in its infancy. That means there are enormous opportunities to solve novel, interesting, and deeply technical problems at all levels of the stack. 2. What is inference?Inference is the second phase of a generative AI model’s lifecycle:
During the past decade’s machine learning (ML) boom, hundreds of thousands of data scientists and ML engineers became familiar with the full lifecycle of training and inference for ML models. Inference for classic ML models is relatively straightforward. In the early days of Baseten, we ran inference for models built with tools like XGBoost on lightweight CPUs with a simple software stack. In contrast, inference for generative AI models is complex. You can’t simply take model weights, get some GPUs, and expect inference to be fast and reliable enough for large-scale production use. Doing inference well requires three layers:
These three layers must work together to create a system that can handle mission-critical inference at scale.
The runtime layer is responsible for ensuring an individual model running on a GPU (or across several GPUs in a single instance) runs as performantly and efficiently as possible. This layer depends on a sophisticated software stack, from CUDA, to PyTorch, to inference engines like vLLM, SGLang, and TensorRT-LLM. Low-level optimization is important, with kernels like FlashAttention delivering significant performance gains. The runtime layer relies on a number of model performance techniques that apply new research to the challenges of inference on generative AI models:
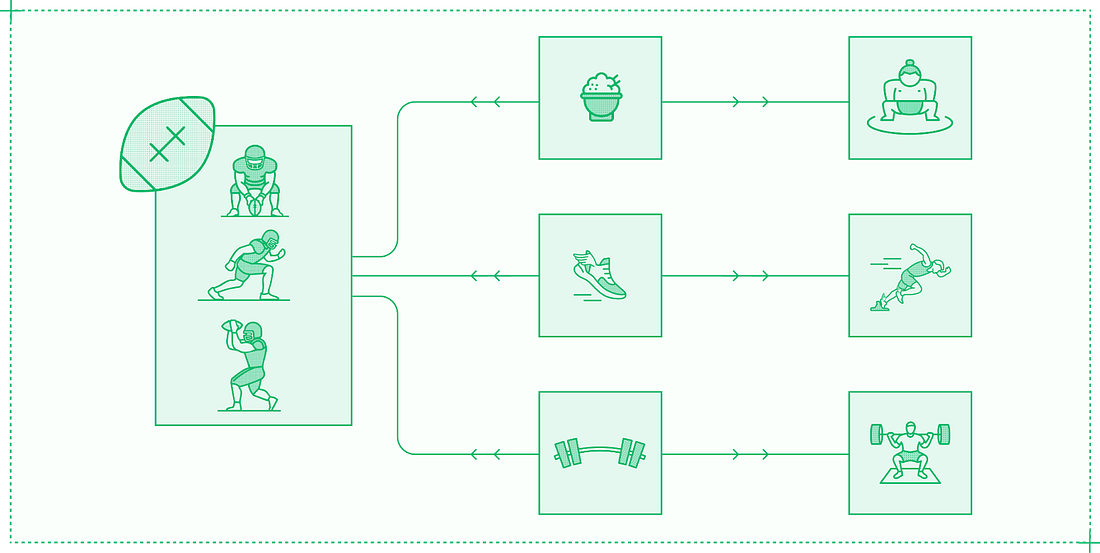
These model performance techniques are used for all modalities and not just LLMs, such as vision language models, embedding models, automatic speech recognition, speech synthesis, image generation, and video generation, which extend the capabilities of AI systems and require their own inference optimizations. But these runtime optimizations are not enough: no matter how performant a single instance of a model server is, it will eventually receive more traffic than it can handle. This is not a CUDA problem or a PyTorch problem, it’s a systems problem that needs to be solved at the infrastructure layer. The nature of infrastructure problems changes at each level of scale. At first, the problems are around autoscaling: knowing when to add and remove replicas, and figuring out how to do so quickly. Past a certain scale – generally a few hundred GPUs – infrastructure problems are defined by capacity. To get access to enough GPUs, inference engineers begin spreading workloads across multiple regions and cloud providers. This quickly leads to silos, where models in one cluster may be starved for resources while other clusters have unused capacity. The final level of scale in infrastructure is a global system that treats all available resources as a single unified pool of compute. Thoughtful multi-cloud infrastructure also improves reliability, protecting against downtime in any individual region or cloud provider. And for global applications, running inference near to end users improves end-to-end latency. Once these runtime and infrastructure capabilities are built, they need to be presented at the appropriate level of abstraction. Inference providers like Baseten and internal teams building inference need to consider what tooling and developer experience to provide as the critical third layer in a complete inference platform. Of course, developer experience is subjective. For inference, one extreme is the black box: give a platform model weights, and get back an API. At the other extreme is providing only basic constructs for compute, network, disk, and so forth. The right developer experience is somewhere in the middle, where inference engineers have enough control to run mission-critical inference confidently, and enough abstraction to work productively. This article – which is an excerpt of Inference Engineering – presents an overview of the technologies and techniques that power inference across all three layers of runtime, infrastructure, and tooling. 3. When is inference engineering needed?Inference engineering adds speed and scale to AI products by optimizing production serving of generative models. Optimization means identifying the best solution from a range of options. Before optimizing model performance and building robust infrastructure, you need to know what “best” means for your product; many performance improvements come from making tradeoffs in latency, throughput, and quality. In practice, optimization is often about finding the right balance, rather than maximizing a single factor. For example, NFL players are big, fast, and strong. But they’re not as big as sumo wrestlers, fast as Olympic sprinters, or strong as champion powerlifters. Their bodies and skills are optimized to fulfill the specific demands of their position over the course of a full season.
Similarly, your inference system must be optimized to fulfill the specific demands of your model, product, and traffic. The more constraints you can introduce, the better the outcomes that can be achieved. You should know:
Early in building an AI product, the answers to these questions may not be clear. At this point, it’s often better to use off-the-shelf APIs whenever possible, rather than investing in dedicated inference. But as a product scales, the requirements become clear and inference engineering becomes a worthwhile pursuit. 4. What hardware does inference use?Inference engineering relies on accelerators: powerful hardware designed to load terabytes of data and perform trillions of operations per second. The most common type of accelerator for inference is the GPU, and the market leader in GPUs for inference is NVIDIA. My book focuses on inference engineering for NVIDIA GPUs in the datacenter, and also covers other vendors of datacenter accelerators and local inference. Across vendors, there are three types of GPUs on the market:
Inference at scale uses datacenter GPUs mounted on racks: refrigerator-sized chassis with standardized power, networking, and cooling. Datacenter GPUs like the NVIDIA B200 offer the highest individual performance, and more importantly, include high-bandwidth GPU-to-GPU interconnects, are installed in highly standardized configurations, and are available by the millions in datacenters worldwide. I doubt there is a B200 GPU running under your desk, but if there is, please send me a picture! Instead, inference on datacenter GPUs runs in one of three modes:
Most inference engineers use cloud GPUs. Large enterprises and governments run on-prem and air-gapped deployments, but cloud-based GPUs offer the flexibility and access that fast-growing AI products need to scale. Even with constraints, navigating the hardware landscape is complex. From variations between cloud providers, to NVIDIA’s personal naming conventions, there are many nuances in selecting the right accelerator. 5. What software does inference use?NVIDIA’s market dominance in the inference space is in no small part due to the robust, mature software ecosystem around its hardware. Hardware iteration cycles are slow. Best-in-class hardware companies like Apple and NVIDIA release new architectures and generations at most annually, with two-year release cycles being more common. But software iteration is fast. Often, to run a newly released open model on day zero, you need to install a nightly build or other pre-release version of each software dependency just to get support for the new model. Software’s fast iteration cycle and lower barrier to entry dramatically expands the landscape of inference engineering. There are countless companies building software at various levels of the inference stack, in contrast to hardware, which centers on NVIDIA and a few competitors. For inference engineers, these are some of the key software players:
There are thousands more companies, universities, and research institutions making essential open-source contributions to inference. Over time, technologies have been built at increasing levels of abstraction:
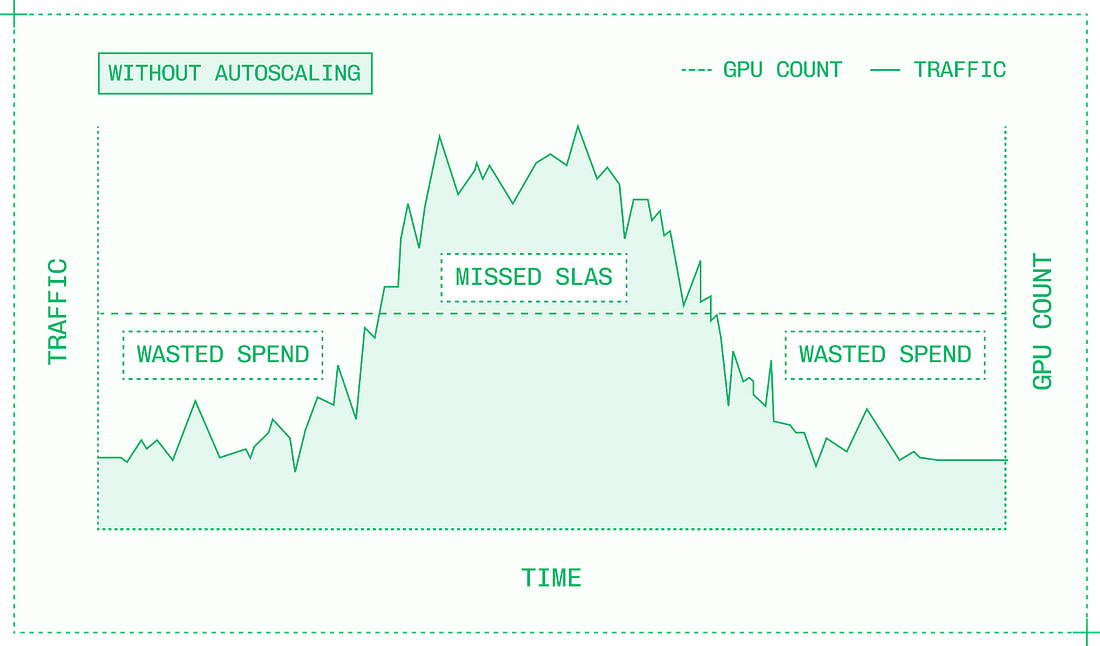
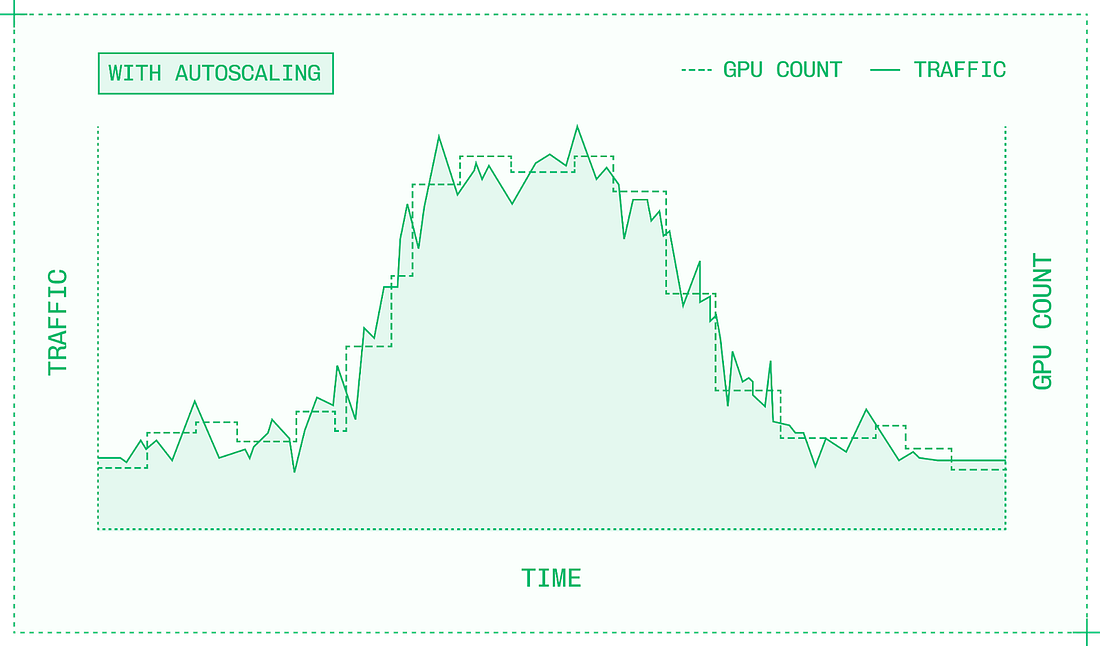
Most inference engineering today happens at the higher levels of abstraction, configuring and deploying inference engines and orchestrating inference across multiple GPUs. No matter which level of the stack you work at, it’s essential to have a strong mental model for the adjacent levels of abstraction to guide your work. 6. What infrastructure does inference need?When you scale production traffic, your assumptions are rigorously tested. Everything from input and output sequence lengths, to traffic patterns, to what topic a user decides to chat about; they all impact your observed performance in production. And maintaining secure, robust infrastructure is an entirely different skillset from optimizing model inference on the GPU. No matter how fast and efficiently a single instance can serve a model, the service will be overwhelmed if traffic gets high enough. It’s an infrastructure problem, not with PyTorch or CUDA, and it requires a different mindset and different technologies. Scaling in production introduces new complexities about where and how to get GPUs, balance traffic across them, and prevent downtime. The goal of autoscaling is to ensure you always have enough resources to serve all incoming requests, while maintaining latency SLAs and without wasting money on idle GPUs.
Autoscaling systems use Kubernetes, an open-source container orchestration system, along with a cluster-level system for provisioning and deallocating compute. Kubernetes can run one or more replicas of a model container, each on its own instance. An instance includes the GPUs and other hardware resources that the container requires. Unless your traffic is unusually consistent, there probably isn’t a specific number of replicas that perfectly matches your needs. Autoscaling is the practice of dynamically adjusting the number of replicas allocated to a given model within a cluster. There are two ways to make autoscaling decisions:
Utilization and traffic don’t always match. For example, in LLM prefill, a few requests with hundreds of thousands of uncached input tokens could cause much higher utilization than many small requests with high cache hit rates. Traffic-based scaling decisions can be made proactively, while utilization is a lagging indicator. Use both in combination to keep system resources matched with demand. When designing a traffic-based autoscaling system, you want to configure five factors:
The exact configuration determines how well the autoscaling system achieves its goals of maintaining latency SLAs without wasting resources. For example, increasing the scale-down delay prevents premature scaledowns for spikey traffic, but could result in unnecessary spend after traffic has properly cooled down. Autoscaling within a single cluster works up to a certain point, but high-volume deployments serving a global user base need thousands of GPUs distributed around the world. It’s straightforward to build multi-cloud inference as a collection of siloed compute across different cloud providers. But in these setups, there’s no way to use inter-cloud compute fluidly, and moving workloads across clouds is a tedious, error-prone process. True multi-cloud inference requires building a multi-region, multi-provider bin packing tool, which treats distinct pools of compute as fungible with each other. Like Kubernetes within a single cluster, multi-cloud capacity management must take a global view, enabling global scheduling.
Running true multi-cloud inference unlocks:
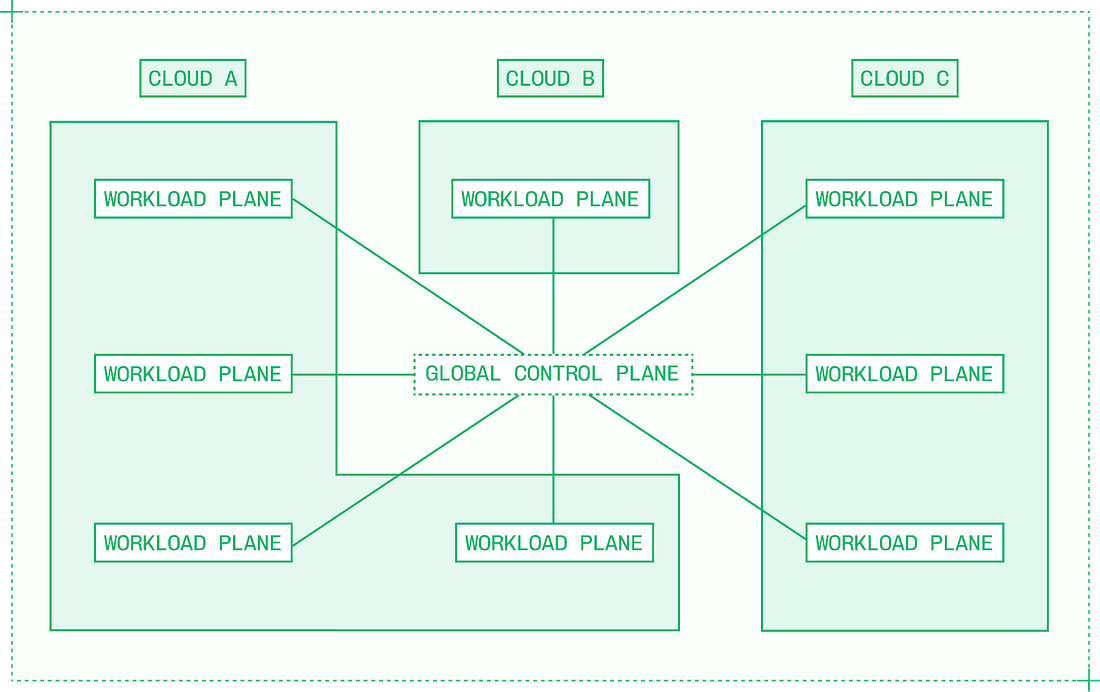
Scaling from one cluster in one cloud to many clusters in many clouds requires a new coordination layer. A multi-cloud architecture contains:
This separation of responsibilities ensures that individual workload planes can serve traffic independently. If something happens to the control plane or any given workload plane, other workloads should be unaffected. 7. Five approaches to make inference fasterOne of the coolest things about working in inference engineering is that, unlike many industries where new academic research takes years or decades to be adopted, techniques from new papers are live in production within months or even weeks. But there is a gap to bridge between research and production, and some of the most visible inference engineering work of all comes from doing so. Real-world traffic defies constraints. But with volume, you can adapt systems over time to match the changing nature of usage. Tuning the parameters of inference engines, speculation algorithms, and model servers isn’t a one-time task. Instead, either through iterative deployments or dynamic runtime adjustments, you can continuously improve the performance of an inference system. Finding the right combination of techniques and configurations takes patient experimentation. I remember an internal hackathon during which one of Baseten’s inference engineers worked on an autocomplete model for code, and ended up trying 77 different configurations via a handwritten script before finding a non-obvious solution that doubled TPS (tokens per second) for a customer’s model. Sometimes, techniques are symbiotic or incompatible, which makes inference optimization even more complex. For example, quantizing the KV cache alleviates a bottleneck in disaggregation, but increasing batch sizing reduces the compute available for speculation. An inference engineer’s challenge is always to create a balanced set of optimizations that delivers more than the sum of its parts. Let’s look into the key categories of applied research for inference acceleration: quantization, speculation, caching, parallelism, and disaggregation. Approach #1: QuantizationQuantization means reducing the numerical precision of a model’s weights. It improves latency (both TTFT [time to first token] and TPS, increases system throughput, and opens up headroom for other optimizations like disaggregation, speculation, and prefix caching to be even more effective. But when it goes wrong, quantization can materially reduce a model’s output quality. Models are trained with weights, activations, and other components represented in a certain native number format. Usually, this is BF16 or FP16, although 8-bit and 4-bit native precisions are becoming more popular for training. Post-training quantization works by changing those model weights and other values from their native number format, to a lower-precision format. Cutting precision in half improves performance in both phases of inference:
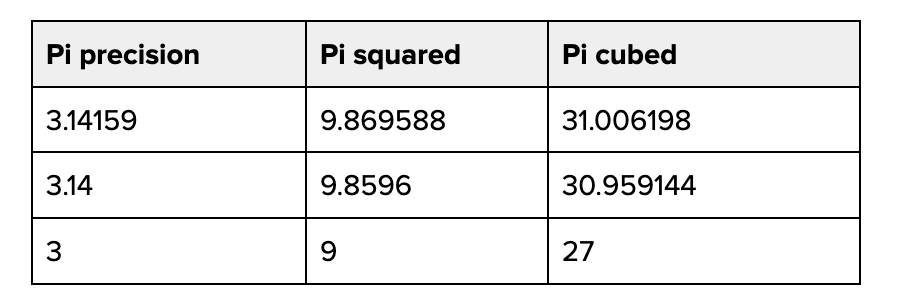
Working with quantized data introduces overheads, so it’s not linearly twice as fast to go from 16 to 8 bits. In practice, quantization down a single level of precision generally offers 30%-50% better performance for LLMs. The catch with quantization is that it runs the risk of reducing a model’s output quality, and has the potential to introduce precision errors throughout the calculations that power inference. Precision errors compound over time. Consider what happens when you square and cube different precisions of Pi:
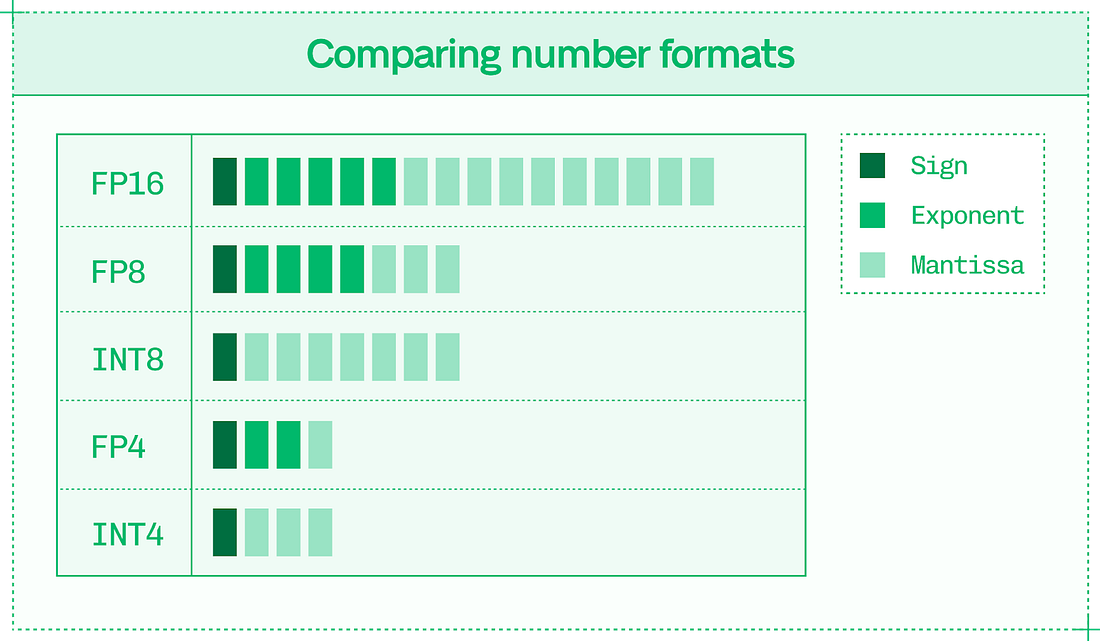
Most of the work in quantization is in preventing precision errors and minimizing their impact on the final model output. Sixteen-bit, 8-bit, and 4-bit precisions are the primary formats for inference. Number formats contain:
Combined, these attributes determine the two factors behind how well a number format represents the values used in inference:
Dynamic range is essential to low-precision inference without quality loss. Sixteen bits can represent 65,536 distinct values, while 8 bits can only represent 256 different values. The dynamic range is the distribution of these values – the difference between the smallest and largest available value. Dynamic range explains why floating-point formats are better than integer formats for inference. Floating-point formats have three properties:
An FP8 number in an E4M3 data format means it has a 4-bit exponent and a 3-bit mantissa, with the remaining bit for the sign. Integer formats only have sign and value bits.
The exponent in floating-point numbers gives it a higher dynamic range, meaning it can better express very large and very small numbers. This is important because outlier values are significant in inference, and floating-point number formats better represent outliers after quantization. Within floating-point formats, there are multiple options at each precision, like FP4, MXFP4, and NVFP4. These formats differ in granularity, or in the number of values quantized by a single scale factor. Quantization can be applied at three levels:
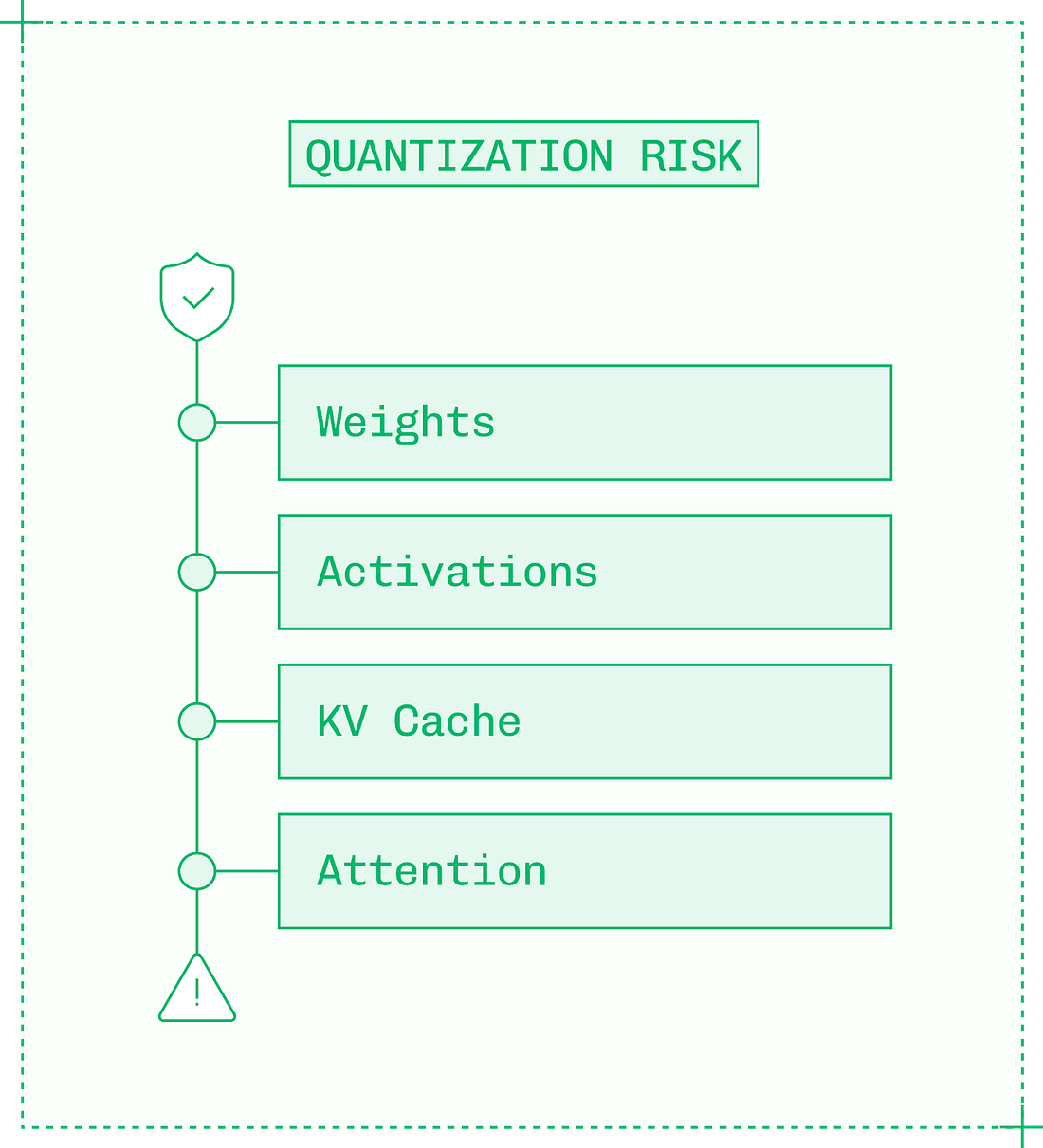
More granular quantization has a lower chance of smoothing over outliers, which preserves quality. However, more granularity also introduces extra overhead for storing and applying scale factors. The components of a model have varying sensitivities to quantization. Reducing the precision of more sensitive components runs a higher risk of quality degradation. From the least to most sensitive components:
Within each component, you can get more selective about quantization. Even in linear layers and activations – generally the least sensitive to quantization due to their size – early and late layers, like the input and output layers of the neural network, may be left in their original precision as these layers are more sensitive. While quantizing weights and activations helps performance, KV cache quantization gives an additional boost to techniques like prefix caching and disaggregation. The KV cache is a valuable resource and quantizing it allows inference engines to store more of it in memory and read it more quickly. However, the KV cache for each token is used by each subsequent token. This means precision errors introduced by quantization can compound from token to token. Compounding errors are exactly why attention layers are the riskiest to quantize: not only is attention very sensitive to dynamic range, but each attention calculation relies on the results of each previous attention calculation. Therefore, over a sequence of thousands of tokens, errors accumulate quickly. All but the most aggressive quantization schemes run functions like softmax in their original precision.
A moderate approach to low-precision inference uses a format like FP8 with high dynamic range – if possible, a microscaling format like MXFP8 – to carefully quantize select linear layers, activations, and often KV cache values. Even with these high dynamic range formats, components of the attention layer are rarely quantized. Approach #2: Speculative decodingThe decode phase of LLM inference is an autoregressive process in which tokens are generated one at a time. The bottleneck on decode is memory bandwidth, with compute sitting idle at low-to-moderate batch sizes as weights are read from memory. Speculative decoding takes advantage of that spare compute to try and generate multiple tokens per forward pass through the target model. If an inference engine could generate two, three, or even more tokens for each round-trip of weights through memory, it would generate far more tokens per second. Note, speculative decoding only improves TPS / ITL (inter-token latency), not TTFT (time to first token.) There are multiple algorithms for speculative decoding and they share a common mechanism:
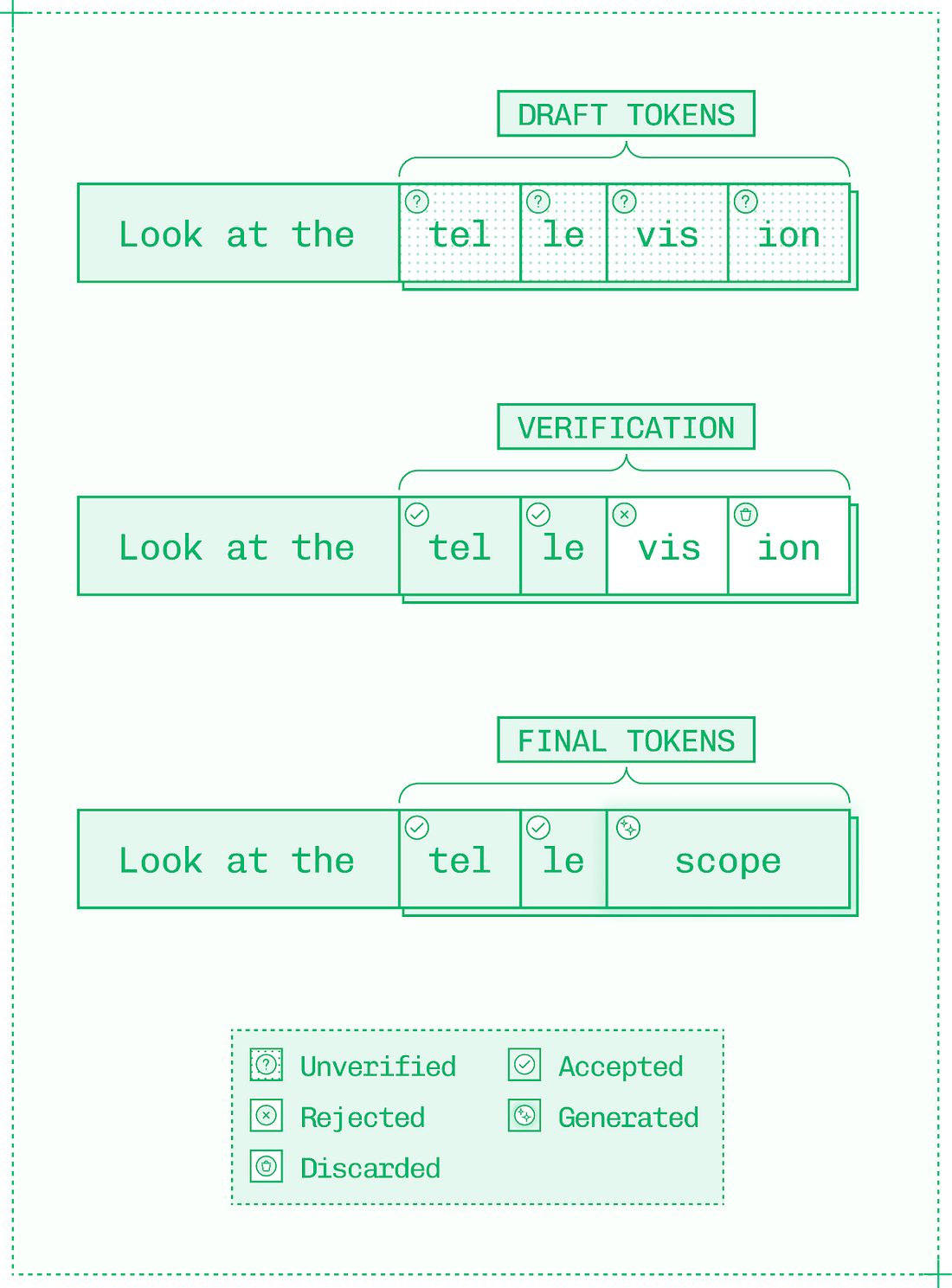
This generates N+1 tokens per forward pass, or iteration through the decode loop, where N is the number of accepted draft tokens. Generating draft tokens is not free, it takes both compute and memory. However, it is much faster for a target model to validate a draft token than to generate an original token. If you imagine a sudoku puzzle, solving it is hard, but checking if the solution is correct is very easy. For the target model, generating a token is like solving a sudoku, while validating a draft token is like checking a finished sudoku. The performance uplift from any speculative decoding strategy depends on three factors:
Token acceptance rate is high early in the draft sequence, but draft tokens get less reliable deeper in the sequence.
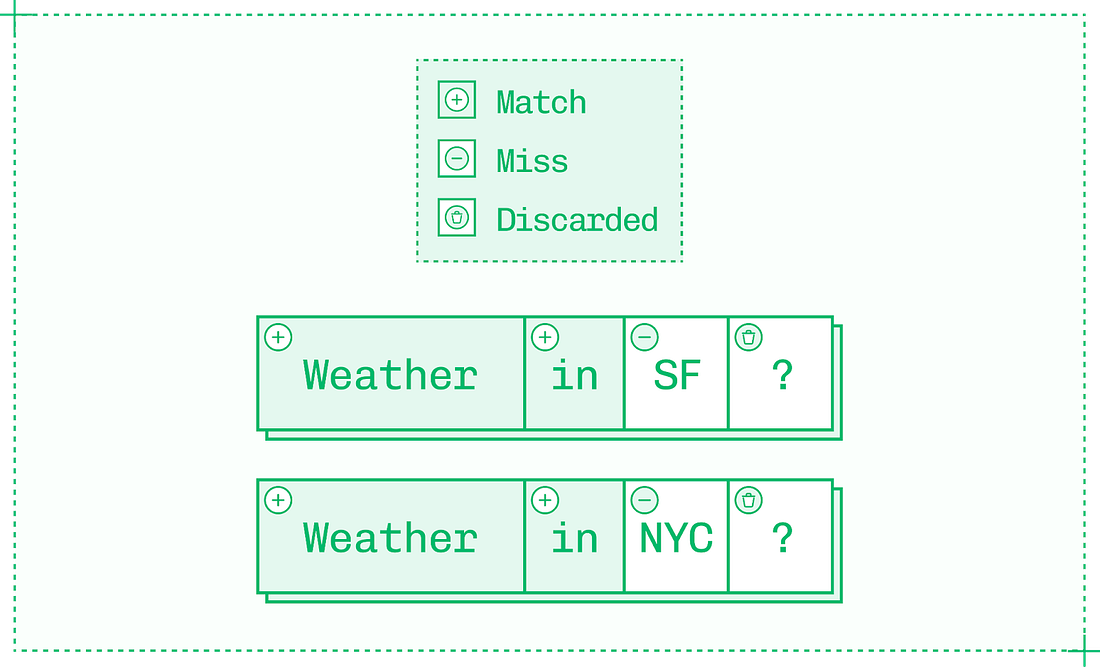
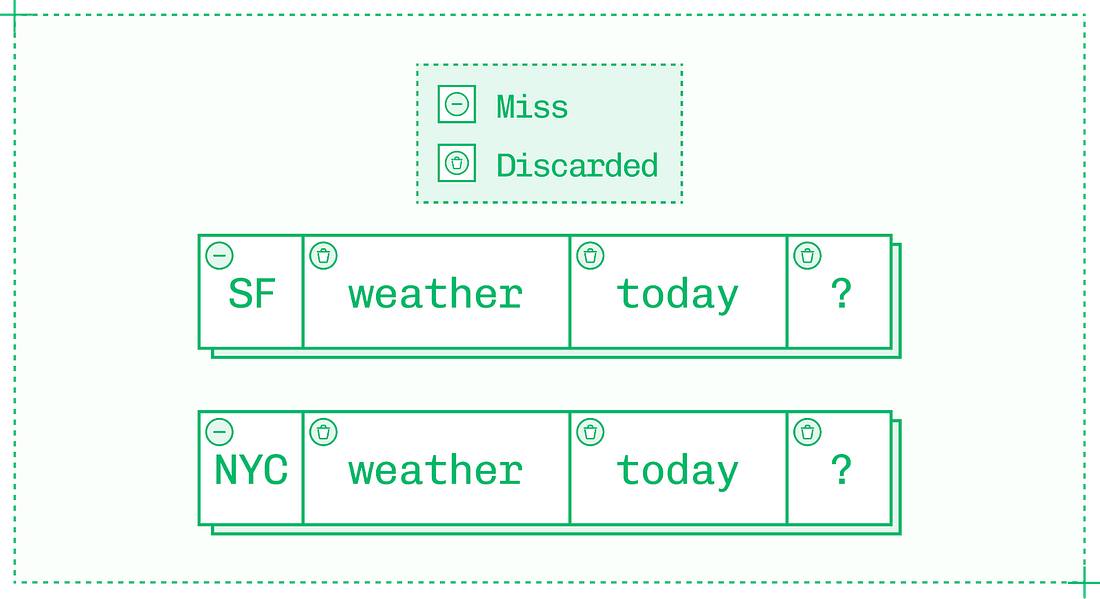
Aim for short, high-percentage sequences because while generating and validating tokens is inexpensive relative to generating tokens in the original model, it still comes with meaningful overhead. Additionally, once a single draft token is rejected as wrong, all subsequent tokens in the sequence are also rejected. Working with speculation is interesting because so many factors affect token acceptance rate. The big one is the temperature parameter – higher temperatures yield token distributions that are harder to predict, reducing the effectiveness of speculative decoding. But even factors as simple as subject matter can make a difference on acceptance rate if the draft model or additional decoder head used for speculation is better versed in, say, math than history. Another limitation on speculative decoding is that it’s most useful at low batch sizes where there are spare compute cycles. At higher batch sizes, speculative decoding must be dynamically disabled as compute is too saturated to afford verification. Each speculation algorithm navigates these tradeoffs differently, and careful implementation of the right algorithm for the situation can lead to major improvements in TPS. Approach #3: CachingDuring prefill, the inference engine builds a KV cache (a store of keys and values for each token) on the input sequence. It then updates the KV cache for each token during decode. As inference is autoregressive, the value for each new token depends on the value of every previous token in the sequence. Every inference engine uses KV caching by default on a request-by-request basis. Without KV caching, LLM inference would be unbearably slow since each previous value in the entire sequence would need to be recalculated for each subsequent token. However, engineers can get more utility from the KV cache by reusing it between requests rather than solely within each inference sequence. Consider the following two prompts, each with four tokens on most tokenizers:
By default, the inference engine has to run prefill on all four tokens of each prompt. But the first tokens of each prompt – “Weather in” – form a shared prefix between the pair. With prefix caching, you can reuse the KV cache from the first request to improve TTFT on the second request by skipping prefill on the first two tokens and reading in the existing KV cache instead. When you see pay-per-token APIs charge less for “cache hit” input tokens than “cache miss” tokens, this is why: reusing cached tokens takes very little compute power and time. As an inference engineer, you can apply the same principle to reduce latency, improve throughput and therefore save money on your own deployments. Saving two tokens won’t make a big impact on TTFT, but prefix caching can skip prefill on thousands of tokens in certain domains:
Prefix caching works from the start of the input sequence until the first non-repeated token. The fourth token in the weather example, a question mark, is shared between the two input sequences. However, the prefix ends at the first non-repeated token, so the fourth token isn’t read from cache. Since prefixes end at the first unique token, your context engineering determines TTFT savings. Consider a different approach to the same prompt:
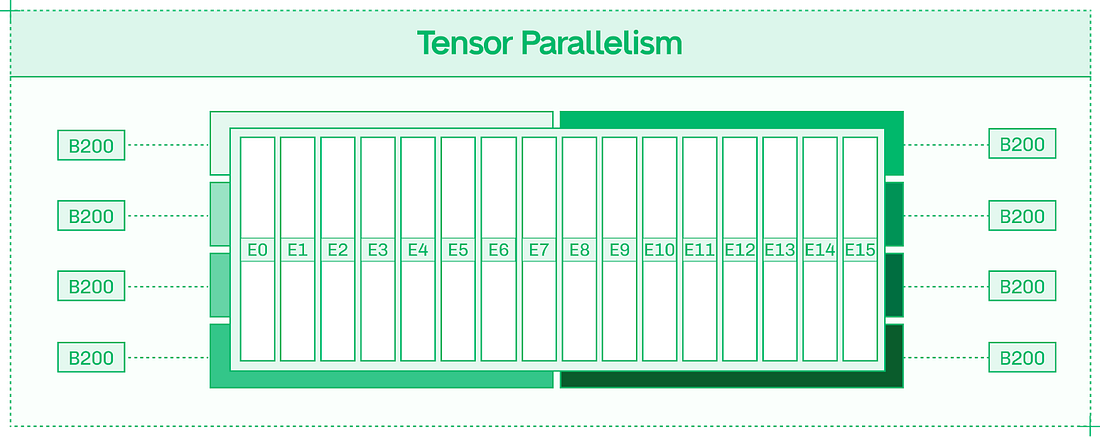
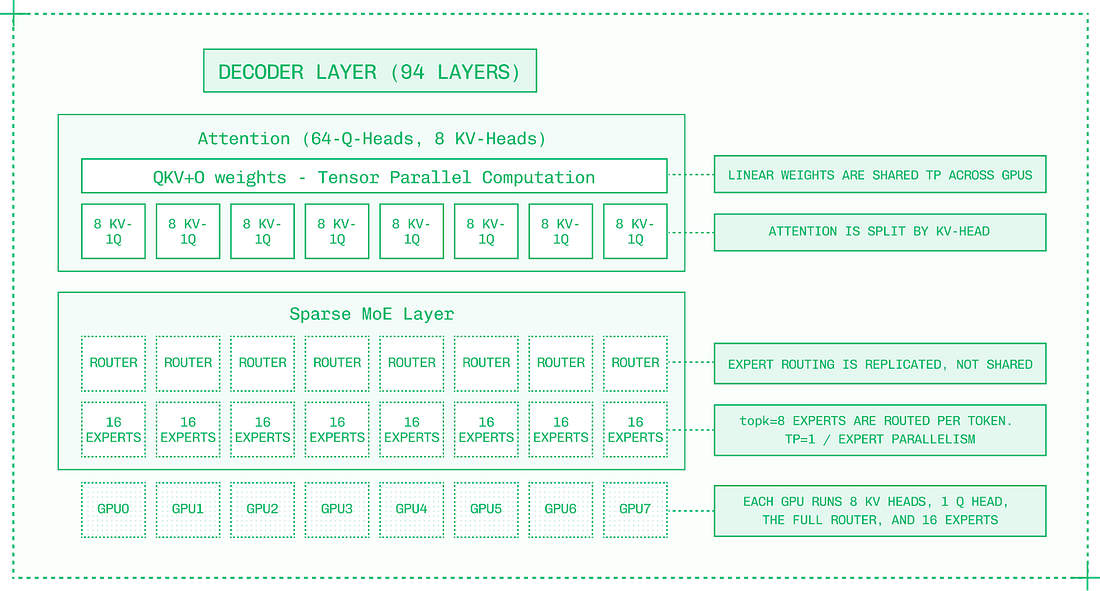
Here, there is no savings from prefix caching, as the very first token differs between the two sequences, even though every subsequent token is the same. To take advantage of prefix caching, ensure that novel tokens are as late in your prompt as possible. Approach #4: ParallelismTensor Parallelism (TP) should be your default strategy for multi-GPU model inference. It supports dense models like Llama 405B, and the MoE (mixture of experts) models that currently dominate the open model landscape.
TP works by splitting apart each layer of the model (as opposed to Pipeline Parallelism, which keeps layers intact) and distributing the layer fragments across the allocated GPUs. For each layer, the expense of reading from weights’ memory and executing matrix multiplication is shared across the GPUs.
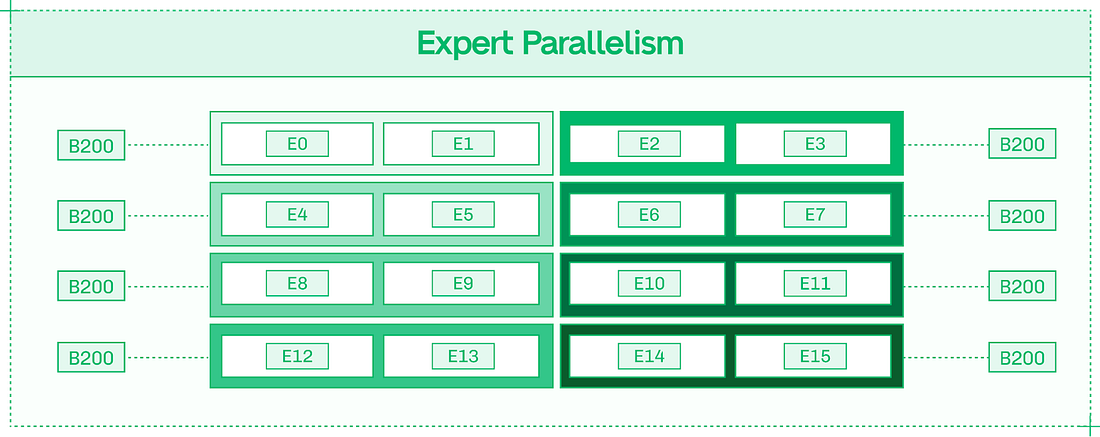
However, the results of each layer need to be communicated in an all-reduce fashion (across all eight GPUs) into a single output before the next layer can be computed. In nodes with high-bandwidth intra-node NVLink and NVSwitch, this communication overhead is minimized. Increasing Tensor Parallelism improves TPS on a per-user basis, assuming the model is large enough and the sequences are long enough that the communication overhead doesn’t outweigh the faster forward pass – which is the case for most frontier models. Expert Parallelism (EP) neatly divides experts across GPUs, so that in a model with 128 experts served in EP8 across eight GPUs, each GPU hosts 16 full experts.
EP improves total system throughput, making inference more scalable and less expensive. With individual experts processing tokens separately, each token takes just as long, but the system as a whole can handle more simultaneous tokens. Many deployments use a mix of TP and EP to achieve both benefits.
EP requires less inter-GPU communication than Tensor Parallelism. The Expert Router, which determines which experts each token activates, is replicated onto each GPU as it is a relatively small component of the model. Inter-GPU communication is necessary for passing tokens from expert to expert, but unlike TP, it is not required to collect the results of each layer. Thanks to this lower communication overhead, EP scales well to multi-node deployments and systems with limited interconnect bandwidth. Approach #5: DisaggregationDisaggregation combines three important ideas in inference engineering:
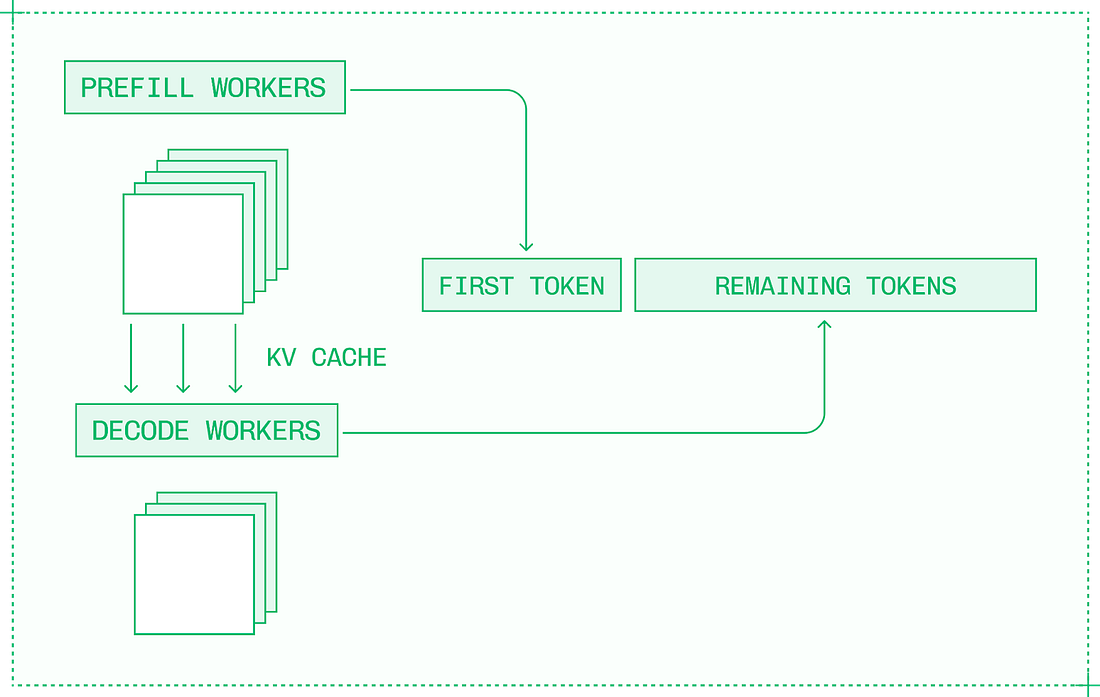
When prefill and decode run on the same node under heavy traffic, they have a higher chance of interfering with one another. Ideally, prefill uses more compute resources, while decode uses more memory, and the two can co-exist efficiently. However, with larger batches and more compute-intensive optimizations, prefill and decode start competing for resources. Disaggregation, or disaggregated serving, is the idea of separating prefill and decode into separate engines on separate GPUs or nodes.
Disaggregation turns LLM inference into a three-step process:
In conditional disaggregation, the request is first sent to the decode engine, which checks if the input sequence is already cached, or is short enough to handle locally:
Conditional disaggregation is better for real-world traffic. Another benefit of disaggregation is that with separate prefill and decode engines, you can optimize each engine individually and the system as a whole. For example, the compute-bound prefill engine requires a lower TP than the memory-bound decode engine. TakeawaysThis is Gergely again. Thanks to Philip for this deepdive into inference engineering, which is around 10% of the contents of his new book, ”Inference Engineering.” If you’d like to go deeper into this topic, you can download the full book for free: This title will also be available in physical, printed form: sign up to the waitlist to be notified when it’s available. It’s encouraging that inference engineering is no longer a “monopoly” belonging to a few leading AI labs. Top AI model makers like OpenAI and Anthropic control all aspects of their AI models – from training to inference – so there’s no inference engineering to be done with them. However, thanks to increasingly capable open models, engineering teams have the opportunity to tweak how they use models, and this is where the theory and practice of inference engineering becomes invaluable. Even so, the discipline of inference engineering still seems to only make sense for a subset of tech companies. To justify investment in inference engineering, you need to be spending big money on inference from vendors. This is the point at which it can make sense to invest time and money to see if you can set up your own inference stack on top of open models, and swap out some existing usage. I wonder if inference engineering is the AI version of the “build vs buy” dilemma. For software-as-a-service (SaaS), the question for every company is whether to build it in-house, or buy from a vendor. For example, should you build a project management software (it’s possible!), or just buy an existing one? And what about feature flagging, not to mention observability? Experienced engineers all understand the pros and cons of building it yourself (time and maintenance, which is a constant drag.) Tuning and operating your own LLM stack is a much newer field, and inference engineering is at the heart of building better inference stacks than what comes “out of the box” with open models. Picking up the basics of inference engineering feels like a valuable skill – and it’s also new and interesting. If you become well-versed in inference engineering, you could create optionality for your own team and company in LLM usage. Running your own inference stack on top of an open model gives control of what you’re running and of pricing. Inference engineering helps create options for achieving better performance from an open model by using the approaches covered in the extract above from Philip’s book. You’re on the free list for The Pragmatic Engineer. For the full experience, become a paying subscriber. Many readers expense this newsletter within their company’s training/learning/development budget. If you have such a budget, here’s an email you could send to your manager. This post is public, so feel free to share and forward it. If you enjoyed this post, you might enjoy my book, The Software Engineer's Guidebook: navigating senior, tech lead, staff and principal positions at tech companies and startups.
|







Comments
Post a Comment