Designing Data-Intensive Applications: The Cloud & Doing the Right Thing
Designing Data-Intensive Applications: The Cloud & Doing the Right ThingHow the cloud changes the way we build applications, and why engineers’ ethical choices matter more than ever. Excerpt from the book, ‘Designing Data-Intensive Applications’, 2nd edition
In 2016, Martin Kleppmann published ‘Designing Data-Intensive Applications’, which quickly became a go-to book for those of us building backend applications and distributed systems. In it, Martin combined his experience as a startup founder with observations from his time at LinkedIn, and invested years of rigorous, fulltime research in the title. Nine years later, he felt the time was ripe for an updated edition, with cloud computing much more widespread than in 2016. So, Martin teamed up with software engineer and investor, Chris Riccomini, a former colleague at LinkedIn and the author of The Missing README, for a full refresh of the book which brings it right up to date for the present day.
Martin was recently on The Pragmatic Engineer Podcast, where we discussed this updated volume and many related cloud computing matters. We also looked into some topics that have become less relevant over time, like details on MapReduce. I asked Martin if this newsletter could share an excerpt of the updated edition of the book about a timeless, important topic, and he generously agreed. So, today we cover:
These excerpts are only part of the book; the first edition has been on my shelf for years and is now in well-worn condition. I jumped at the chance to get the second edition, and if you’re interested in building resilient systems, I recommend it as an excellent resource. My usual disclaimer: as with all my recommendations, I was not paid for this article, and none of the links are affiliates. See my ethics statement for more. The bottom of this article could be cut off in some email clients. Read the full article uninterrupted, online. The excerpt below is from “Designing Data-Intensive Applications” second edition, by Martin Kleppmann and Chris Riccomini. Copyright © 2026 Martin Kleppmann, Chris Riccomini. Published by O’Reilly Media, Inc. Used with permission. 1. Cloud versus self-hosting tradeoffsThis excerpt is from Chapter 1: “Trade-Offs in Data Systems Architecture” For anything that an organization needs to do, one of the first questions is whether it should be done in-house or outsourced. That is, should you build or should you buy? Ultimately, this is a question about business priorities. A common rule of thumb is that things that are a core competency or a competitive advantage of your organization should be done in-house, whereas things that are non-core, routine, or commonplace should be left to a vendor [20]. To give an extreme example, most companies do not fabricate their own CPUs, since it is cheaper to buy them from the semiconductor manufacturers. With software, two important decisions to be made are who builds the software and who deploys it. The spectrum of possibilities is illustrated in Figure 1-2. At one extreme is bespoke software that you write and run in-house; at the other extreme are widely-used cloud services or SaaS products that are implemented and operated by an external vendor and that you access only through a web interface or API.
The middle ground is off-the-shelf software (open source or commercial) that you self-host, or deploy yourself – for example, if you download MySQL and install it on a server you control. This could be on your own hardware (often called ‘on-premises,’ even if the server is in a rented datacenter rack and not literally on your own premises), or on a virtual machine (VM) in the cloud (infrastructure as a service, or IaaS). There are more points along this spectrum, such as taking open source software and running a modified version of it. A related question is how you deploy services, either in the cloud or on premises – for example, whether you use an orchestration framework such as Kubernetes. However, choice of deployment tooling is beyond the scope of this book, since other factors have a greater influence on the architecture of data systems. Pros & Cons of Cloud ServicesUsing a cloud service, rather than running comparable software yourself, essentially outsources the operation of that software to the cloud provider. There are good arguments for and against this approach. Cloud providers claim that using their services saves time and money and allows you to move faster compared to setting up your own infrastructure. Whether using a cloud service is actually cheaper and easier than self-hosting depends very much on your skills and the workload on your systems, however. If you already have experience of setting up and operating the systems you need, and if your load is quite predictable (i.e., the number of machines you need does not fluctuate wildly), then it’s often cheaper to buy your own machines and run the software on them yourself [21, 22]. On the other hand, if you need a system that you don’t already know how to deploy and operate, adopting a cloud service is often easier and quicker than learning to manage the system. Hiring and training staff specifically to maintain and operate the system can get very expensive. You still need an operations team when you’re using the cloud, but outsourcing the basic system administration can free up your team to focus on higher-level concerns. Outsourcing the operation of a system to a company that specializes in running it can potentially result in better service, since the provider gains operational expertise from providing the service to many customers. On the other hand, if you run the service, you can configure and tune it to perform well on your particular workload. A cloud service would likely be unwilling to make such customizations on your behalf. Cloud services are particularly valuable if the load on your systems varies a lot over time. If you provision your machines to be able to handle peak load, but those computing resources are idle most of the time, the system becomes less cost-effective. In this situation, cloud services have the advantage that they can make it easier to scale your computing resources up or down in response to changes in demand. For example, analytical systems often have extremely variable load. Running a large analytical query quickly requires a lot of computing resources in parallel, but once the query completes, those resources sit idle until a user makes the next query. Predefined queries (e.g., for daily reports) can be enqueued and scheduled to smooth out the load, but for interactive queries, the faster you want them to complete, the more variable the workload becomes. If your dataset is so large that querying it quickly requires significant computing resources, using the cloud can save money as you can return unused resources to the provider rather than leaving them idle. For smaller datasets, this difference is less significant. The biggest downside of a cloud service is that you have no control over it:
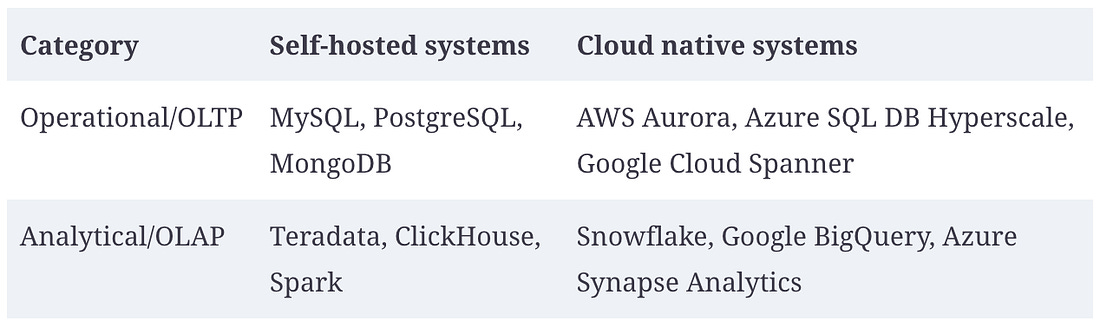
Despite all these risks, it has become more and more popular for organizations to build new applications on top of cloud services, or to adopt a hybrid approach in which cloud services are used for some aspects of a system. However, cloud services will not subsume all in-house data systems. Many older systems predate the cloud, and for any services that have specialist requirements that existing cloud services cannot meet, in-house systems remain necessary. For example, very latency-sensitive applications such as high-frequency trading require full control of the hardware. Cloud-Native System ArchitectureBesides having a different economic model (subscribing to a service instead of buying hardware and licensing software to run on it), the rise of the cloud has also had a profound effect on how data systems are implemented on a technical level. The term “cloud native” is used to describe an architecture that is designed to take advantage of cloud services. In principle, almost any software that you can self-host could also be provided as a cloud service, and indeed, such managed services are now available for many popular data systems. However, systems that have been designed from the ground up to be cloud native have been shown to have several advantages: better performance on the same hardware, faster recovery from failures, being able to quickly scale computing resources to match the load, and supporting larger datasets [24, 25, 26]. Table 1-2 lists some examples of both types of systems.
Layering of cloud servicesMany self-hosted data systems have simple system requirements; they run on a conventional operating system such as Linux or Windows, they store their data as files on the filesystem, and they communicate via standard network protocols such as TCP/IP. A few systems depend on special hardware such as GPUs (for ML) or remote direct memory access (RDMA) network interfaces, but on the whole, self-hosted software tends to use generic computing resources: CPUs, RAM, a filesystem, and an IP network. In a cloud, this type of software can be run in an IaaS environment, using one or more VMs (or instances) with a certain allocation of CPUs, memory, disk, and network bandwidth. Compared to physical machines, cloud instances can be provisioned faster and come in a greater variety of sizes, but otherwise they are similar to traditional computers: you can run any software you like on them, but you are responsible for administering it yourself. In contrast, the key idea of cloud-native services is not only to use the computing resources managed by your operating system, but also to build upon lower-level cloud services to create higher-level services. For example:
As always with abstractions in computing, there is no one right answer to what you should use. As a general rule, higher-level abstractions tend to be more oriented toward particular use cases. If your needs match the situations for which a higher-level system is designed, using the existing higher-level system will probably meet your needs with much less hassle than building it yourself from lower-level systems would. On the other hand, if no high-level system meets your needs, building it yourself from lower-level components is the only option. Separation of storage and computeIn traditional computing, disk storage is regarded as durable (we assume that once something is written to disk, it will not be lost). To tolerate the failure of an individual hard disk, RAID (redundant array of independent disks) is often used to maintain copies of the data on several disks attached to the same machine. RAID can be implemented either in hardware or in software by the operating system, and it is transparent to the applications accessing the filesystem. In the cloud, compute instances (VMs) may also have local disks attached, but cloud-native systems typically treat these disks more like an ephemeral cache and less like long-term storage. This is because the local disk becomes inaccessible if the associated instance fails, or if the instance is replaced with a bigger or a smaller one (on a different physical machine) to adapt to changes in load. As an alternative to local disks, cloud services also offer virtual disk storage that can be detached from one instance and attached to a different one (e.g., Amazon EBS, Azure managed disks, and persistent disks in Google Cloud). Such a virtual disk is not a physical disk, but rather a cloud service provided by a separate set of machines that emulates the behavior of a disk (a block device, where each block is typically 4 KiB in size). This technology makes it possible to run traditional disk-based software in the cloud, but the block device emulation introduces overheads that can be avoided in systems that are designed from the ground up for the cloud [24]. The use of virtual disks also makes the application very sensitive to network glitches, since every I/O operation on the virtual block device is a network call [27]. To address this problem, cloud-native services generally avoid using virtual disks and instead build on dedicated storage services that are optimized for particular workloads. Object storage services such as S3 are designed for long-term storage of fairly large files, ranging from hundreds of kilobytes to several gigabytes in size. The individual rows or values stored in a database are typically much smaller than this; cloud databases therefore typically manage smaller values in a separate service and store larger data blocks (containing many individual values) in an object store [25, 28]. In traditional systems architecture, the same computer is responsible for both storage (disk) and computation (CPU and RAM), but in cloud-native systems, these two responsibilities have become somewhat separated, or disaggregated [9, 26, 29, 30]: for example, S3 only stores files, and if you want to analyze that data, you will have to run the analysis code somewhere outside of S3. This implies transferring the data over the network. Furthermore, cloud-native systems are often multitenant, which means that rather than having a separate machine for each customer, data and computation from several customers are handled on the same shared hardware by the same service [31]. Multitenancy can enable better hardware utilization, easier scalability, and easier management by the cloud provider, but it also requires careful engineering to ensure that one customer’s activity does not affect the performance or security of the system for other customers [32]. Operations in the Cloud EraTraditionally, the people managing an organization’s server-side data infrastructure were known as database administrators (DBAs), or system administrators (sysadmins). More recently, many organizations have tried to integrate the roles of software development and operations into teams with a shared responsibility for both backend services and data infrastructure; the DevOps philosophy has guided this trend. Site reliability engineers (SREs) are Google’s implementation of this idea [33]. The role of operations is to ensure that services are reliably delivered to users (including configuring infrastructure and deploying applications) and to ensure a stable production environment (including monitoring and diagnosing any problems that may affect reliability). For self-hosted systems, operations traditionally involve a significant amount of work at the level of individual machines, such as capacity planning (e.g., monitoring available disk space and adding more disks before you run out of space), provisioning new machines, moving services from one machine to another, and installing operating system patches. Many cloud services present an API that hides the individual machines implementing the service. For example, cloud storage replaces fixed-size disks with metered billing, where you can store data without planning your capacity needs in advance, and you are then charged based on the space used. Moreover, many cloud services remain highly available, even when individual machines have failed. This shift in emphasis from individual machines to services has been accompanied by a change in the role of operations. The high-level goal of providing a reliable service remains the same, but the processes and tools have evolved. The DevOps/SRE philosophy places greater emphasis on the following:
With the rise of cloud services, a bifurcation of roles has occurred. Operations teams at infrastructure companies specialize in the details of providing a reliable service to a large number of customers, while the customers of the service spend as little time and effort as possible on infrastructure [35]. Customers of cloud services still require operations, but they focus on different aspects, such as choosing the most appropriate service for a given task, integrating services with each other, and migrating from one service to another. Even though metered billing removes the need for capacity planning in the traditional sense, it’s still important to know what resources you are using for which purpose so that you don’t waste money on cloud resources that are not needed. Capacity planning becomes financial planning, and performance optimization becomes cost optimization [36]. Additionally, cloud services do have resource limits or quotas (such as the maximum number of processes you can run concurrently), which you need to know about and plan for before you run into them [37]. Adopting a cloud service can be easier and quicker than provisioning and running your own infrastructure, although you still have to learn how to use the cloud service and perhaps work around its limitations. Integration among services becomes a particular challenge as a growing number of vendors offer an ever-broader range of cloud services targeting different use cases [38, 39]. ETL is only part of the story; operational cloud services also need to be integrated with each other. At present, we lack standards to facilitate this sort of integration, so it often involves significant manual effort. Other operational aspects that cannot fully be outsourced to cloud services include maintaining the security of an application and the libraries it uses, managing the interactions between your own services, monitoring the load on your services, and tracking down the cause of problems such as performance degradations or outages. While the cloud is changing the role of operations, the need for operations is as great as ever. 2. Doing the right thing as a software engineerThe excerpt below is a section from Chapter 14, “Doing the Right Thing” In the final chapter of this book, let’s take a step back. Throughout, we have examined a wide range of architectures for data systems, evaluated their pros and cons, and explored techniques for building reliable, scalable, and maintainable applications. However, we have left out a fundamental part of the discussion, which we should now fill in. Every system is built for a purpose; every action we take has both intended and unintended consequences. The purpose may be as simple as making money, but the consequences may be far-reaching. We, the engineers building these systems, have a responsibility to carefully consider those consequences and to ensure that our decisions do not cause harm. We talk about data as an abstract thing, but remember that many datasets are about people: their behavior, their interests, their identities. We must treat such data with humanity and respect. Users are humans too, and human dignity is paramount [1]. Software development increasingly involves making important ethical choices. There are guidelines to help software engineers navigate these issues, such as the ACM Code of Ethics and Professional Conduct [2], but they are rarely discussed, applied, or enforced in practice. As a result, engineers and product managers sometimes take a cavalier attitude to privacy and the potential negative consequences of their products [3, 4]. A technology is not good or bad in itself – what matters is how it is used and how it affects people. This is true of a software system such as a search engine in much the same way as it is for a weapon like a gun. The ethical responsibility is ours to bear; it is not sufficient for software engineers to focus exclusively on the technology and ignore its consequences. In contrast to much of computing, however, the concepts at the heart of ethics are not fixed or determinate in their precise meaning; they require interpretation, which may be subjective [5]. What makes something “good” or “bad” is not well defined, and serious discourse on the subject among computing professionals is lacking [6]. Reasoning about ethics is difficult, but also too important to ignore. What does this entail? “Ethics” are not a checklist with which to comply; it’s a participatory and iterative process of reflection, in dialogue with people involved and accountability for the results [7]. Predictive AnalyticsPredictive analytics is a major part of why people are excited about big data and AI. It’s also an area that is fraught with ethical dilemmas. Using data analysis to predict the weather, or the spread of diseases, is one thing [8]; it is another matter to predict whether a convict is likely to reoffend, whether an applicant for a loan is likely to default, or whether an insurance customer is likely to make expensive claims [9]. The latter have a direct effect on people’s lives. Naturally, payment networks want to prevent fraudulent transactions, banks want to avoid bad loans, airlines want to avoid hijackings, and companies want to avoid hiring ineffective or untrustworthy people. From their point of view, the cost of a missed business opportunity is low, but the cost of a bad loan or a problematic employee is much higher, so it is expected for organizations to be cautious. If in doubt, they are better off saying “no”. However, as algorithmic decision making becomes more widespread, someone who has (accurately or falsely) been labeled as risky by an algorithm may suffer a large number of “no” decisions. Systematically being excluded from jobs, air travel, insurance coverage, property rental, financial services, and other key aspects of society is such a large constraint on an individual’s freedom that it has been called “algorithmic prison” [10]. In countries that respect human rights, the criminal justice system presumes innocence until proven guilty; on the other hand, automated systems can systematically and arbitrarily exclude a person from participating in society without any proof of guilt and little chance of appeal. Bias & discriminationDecisions made by an algorithm are not necessarily any better or any worse than those made by a human. Everyone is likely to have biases, even if they actively try to counteract them, and discriminatory practices can become culturally institutionalized. There is hope that basing decisions on data, rather than subjective and instinctive human assessments, could be more fair and give a better chance to people who are often overlooked or disadvantaged in the traditional system [11]. When we develop predictive analytics and AI systems, we are not merely automating a human’s decision by using software to specify the rules for when to say “yes” or “no”; we are leaving the rules themselves to be inferred from data. However, the patterns learned by these systems are opaque: even if the data indicates a correlation, we may not know why. If the input to an algorithm carries a systematic bias, the system will most likely learn and amplify that bias in its output [12]. In many countries, anti-discrimination laws prohibit treating people differently depending on protected traits such as ethnicity, age, gender, sexuality, disability, or beliefs. Other features of a person’s data may be analyzed, but what happens if they are correlated with protected traits? For example, in racially segregated neighborhoods, a person’s postal code or even their IP address is a strong predictor of race. Put like this, it seems ridiculous to believe that an algorithm could somehow take biased data as input and produce fair and impartial output from it [13, 14]. Yet this belief often seems to be implied by proponents of data-driven decision making; an attitude that has been satirized as “machine learning is like money laundering for bias” [15]. Predictive analytics systems merely extrapolate from the past; if the past is discriminatory, they codify and amplify that discrimination [16]. If we want the future to be better than the past, moral imagination is required, and that’s something only humans can provide [17]. Data and models should be our tools, not our masters. Responsibility and AccountabilityAutomated decision-making raises the question of responsibility and accountability [17]. If a human makes a mistake, they can be held accountable, and the person affected by the decision can appeal. Algorithms make mistakes too, but who is accountable when they go wrong? [18] When a self-driving car causes an accident, who is responsible? If an automated credit scoring algorithm systematically discriminates against people of a particular race or religion, is there any recourse? If a decision by your ML system comes under judicial review, can you explain to the judge how the algorithm made its decision? People should not be able to evade responsibility by blaming an algorithm. Credit rating agencies are a classic example of collecting data to make decisions about people. A bad credit score makes life difficult, but at least a credit score is normally based on relevant facts about a person’s actual borrowing history, and any errors in the record can be corrected (although the agencies normally do not make this easy). Scoring algorithms based on machine learning, however, typically use a much wider range of inputs and are much more opaque, making it harder to understand how a particular decision has come about and whether someone is being treated in an unfair or discriminatory way [19]. A credit score summarizes “how did you behave in the past?” whereas predictive analytics usually work on the basis of “who is similar to you, and how did people like you behave in the past?” Drawing parallels to others’ behavior implies stereotyping people; for example, based on where they live (a close proxy for race and socioeconomic class). What about people put in the wrong bucket? Furthermore, if a decision is incorrect because of erroneous data, recourse is almost impossible [17]. Much data is statistical in nature, which means that even if the probability distribution on the whole is correct, individual cases may well be wrong. For example, if the average life expectancy in your country is 80 years, that doesn’t mean you’re expected to drop dead on your 80th birthday. From the average and the probability distribution, you can’t say much about the age to which someone will live. Similarly, the output of a prediction system is probabilistic and may well be wrong in individual cases. A blind belief in the supremacy of data for making decisions is not only delusional, but also positively dangerous. As data-driven decision making becomes more widespread, we will need to figure out how to avoid reinforcing existing biases, how to make algorithms accountable and transparent, and how to fix them when they inevitably make mistakes. We will also need to figure out how to realize the positive potential of data and prevent it from being used to harm people. For example, analytics can reveal financial and social characteristics about personal lives. On the one hand, this power could be used to focus aid and support to help those who need it most. On the other hand, it is sometimes used by predatory businesses seeking to identify vulnerable people and sell them risky products such as high-cost loans or worthless college degrees [17, 20]. Feedback loopsEven with predictive applications with less immediately far-reaching effects on people, such as recommendation systems, there are difficult issues that we must confront. When services become good at predicting the content users want to see, they may end up showing them only opinions they already agree with, leading to echo chambers in which stereotypes, misinformation, and polarization can breed. We already know the impact that social media echo chambers can have on election campaigns. When predictive analytics affect people’s lives, particularly pernicious problems arise because of self-reinforcing feedback loops. For example, consider the case of employers using credit scores to evaluate potential hires. You may be a good worker with a good credit score, but suddenly find yourself in financial difficulties due to a misfortune beyond your control. As you miss payments on your bills, your credit score suffers, and you will be less likely to find work. Joblessness pushes you toward poverty, which further worsens your score, making it even harder to find employment [17]. It’s a downward spiral due to poisonous assumptions, hidden behind a camouflage of mathematical rigor and data. As another example of a feedback loop, economists found that when gas stations in Germany introduced algorithmic prices, competition was reduced and prices for consumers went up because the algorithms learned to collude [21]. We can’t always predict when such feedback loops may happen. However, many consequences can be predicted by thinking about an entire system (not just the computerized parts, but also the people interacting with it), in an approach known as “systems thinking” [22]. We can try to understand how a data analysis system responds to different behaviors, structures, or characteristics. Does the system reinforce and amplify existing differences between people (e.g., making the rich richer or the poor poorer), or does it try to combat injustice? Even with the best intentions, we must beware of the possibility of unintended consequences. SurveillanceThe excerpt below is from another section in Chapter 14, “Doing the Right Thing” As a thought experiment, try replacing the word “data” with “surveillance”, and observe whether common phrases still sound so good [23]. How about this: “In our surveillance-driven organization we collect real-time surveillance streams and store them in our surveillance warehouse. Our surveillance scientists use advanced analytics and surveillance processing in order to derive new insights.” This thought experiment is unusually polemical for this book, “Designing Surveillance-Intensive Applications”, but strong words are needed to emphasize this point. In our attempts to make software “eat the world” [24], we have built the greatest mass surveillance infrastructure ever seen. We are rapidly approaching a world in which every inhabited space contains at least one internet-connected microphone, in the form of smartphones, smart TVs, voice-controlled assistant devices, baby monitors, and even children’s toys that use cloud-based speech recognition. Many of these devices have terrible security track records [25]. What is new compared to the past is that digitization has made it easy to collect large amounts of data about people. Surveillance of our location and movements, our social relationships and communications, our purchases and payments, and our health data has become almost unavoidable. A surveillance organization may end up knowing more about a person than that person knows about themselves; for example, identifying illnesses or economic problems before that individual is aware of them. Even the most totalitarian, repressive regimes of the past could only dream of putting a microphone in every room and forcing every person to constantly carry a device capable of tracking their location and movements. Yet the benefits that we get from digital technology are so great that we now voluntarily accept this state of total surveillance. The difference is just that the data is being collected by corporations to provide us with services, rather than government agencies seeking control [26]. Not all data collection necessarily qualifies as surveillance, but examining it as such can help us understand our relationship with the data collector. Why are we seemingly happy to accept surveillance by corporations? Perhaps you feel you have nothing to hide; in other words, you are totally in line with existing power structures, you are not a marginalized minority, and you needn’t fear persecution [27]. Not everyone is so fortunate. Or perhaps it’s because the purpose seems benign; it’s not overt coercion and conformance, merely better recommendations and more personalized marketing. However, combined with the discussion of predictive analytics from the last section, that distinction seems less clear. We are already seeing behavioral data about driving, tracked by vehicles without drivers’ consent, affecting their insurance premiums [28], and health insurance coverage that depends on people wearing a fitness tracking device. When surveillance is used to make decisions that hold sway over important aspects of life, such as insurance coverage or employment, it starts to appear less benign. Data analysis can also reveal surprisingly intrusive things; for example, the movement sensor in a smartwatch or fitness tracker can be used to work out what you are typing (e.g., passwords) with fairly good accuracy [29]. Sensor accuracy and algorithms for analysis are only going to get better. TakeawaysThanks to Martin for writing this book, and to himself and Chris for doing a revamp for the second edition. The volume is now even more relevant to how we build systems in 2026 and beyond. You can purchase a hard copy from the publisher’s website or Amazon. The first edition has a timeless quality because it focused on the fundamentals of large systems, and the new second edition follows the same approach, as laid out in its preface:
Since the first edition appeared nine years ago, some things have changed in the tech industry:
If I had to summarize the evolution of the book in its second edition, it would be more focus on cloud and AI, and more on local-first software, testing, and how regulations affect engineers. Interestingly, this mirrors how the tech industry has developed over time, too. I very much appreciate that the book closes with the final chapter focused on “doing the right thing” as a software engineer. Software systems have wide-ranging societal impact, and engineers working on these systems have a great say in what gets built, and how it gets built. As engineers, we owe it the very least to ourselves to consider the broader impact of our decisions — and doing so might also force us to make important ethical choices. There’s less discussion of the ethics angle on software engineering: and I’m glad that Martin and Chris did not shy away from going deeper into this topic. If you’d like to get more background on the book – and on the hard parts of building large-scale systems – check out our podcast episode with Martin Kleppmann. You’re on the free list for The Pragmatic Engineer. For the full experience, become a paying subscriber. Many readers expense this newsletter within their company’s training/learning/development budget. If you have such a budget, here’s an email you could send to your manager. This post is public, so feel free to share and forward it. If you enjoyed this post, you might enjoy my book, The Software Engineer's Guidebook: navigating senior, tech lead, staff and principal positions at tech companies and startups.
|






Comments
Post a Comment