The Pulse: AI load breaks GitHub – why not other vendors?
The Pulse: AI load breaks GitHub – why not other vendors?GitHub’s leadership blames the 3.5x increase in service load as the cause of degradation – or it might be self-inflicted.
Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover Big Tech and startups through the lens of senior engineers and engineering leaders. Today, we cover one out of four topics from last week’s The Pulse issue. Full subscribers received the article below seven days ago. If you’ve been forwarded this email, you can subscribe here. GitHub’s reliability has been beyond unacceptable recently: last month, third party measurements pinned it at one nine (right at 90%). This month, reliability has been down to zero nines – 86% – as per a third-party tracker, and last week, things got even worse: a frankly embarrassing data integrity incident, more outages, and a partial explanation from GitHub, eventually. Data integrity incidentLast Thursday (23 April), this happened: PRs merged via the merge queue using the squash merge method produced incorrect merge commits, when the merge group contained more than one PR. Commits were reverted from subsequent merges: basically, commits were “lost” in the code that was merged! Thanks to a bug GitHub introduced, the service broke its integrity promise that pull requests would be merged as expected when using squash merge, which is a technique typically used to merge multiple small commits into a single, meaningful commit. This is a big deal: as data integrity promises are some of the most important ones, for services like GitHub. A total of 2,092 pull requests were impacted, and companies hit by the outage included Modal and Zipline. Effectively, GitHub pushed a bunch of work on affected customers who had to manually untangle and recover lost commits, which GitHub could offer zero assistance with. Customers had to manually go through their git history and restore missing code. After following manual recovery steps (reverting the squash commit and re-applying commits one by one), all commits should have been recovered. GitHub later emailed the list of affected commits to customers, but it’s odd that GitHub executives seemed to downplay the nature of this outage. After all, an outage that messes with data integrity is a much bigger deal than something like a fall in availability where no data is corrupted. Can Duruk, software engineer at Modal, was unhappy about GitHub’s muted response to the outage:
Outages don’t stopOn Monday (27 April), pull requests and issues disappeared from GitHub’s web UI:
This had to do with an Elasticsearch outage on GitHub’s backend: the cluster became overloaded and went down. So, while pull requests, issues, and projects didn’t vanish altogether, they also didn’t show up during the 6-hour-long outage. There were other outages this week:
Also on Tuesday (28 April), security firm Wiz disclosed a critical security issue, where a bad actor could get access to all repositories on GitHub and GitHub Enterprise server by using only a git push command. GitHub fixed the issue on GitHub.com within six hours, but GitHub Enterprise servers that were not updated remain vulnerable. Famous open source contributor quits GitHub in frustrationOn Tuesday, Mitchell Hashimoto, founder of HashiCorp, creator of Ghostty, announced GitHub was unfit for professional work and that he was moving off to Ghostty, the open source terminal that’s his main focus. Mitchell’s reasoning was dead simple: being on GitHub makes him unproductive (emphasis mine:)
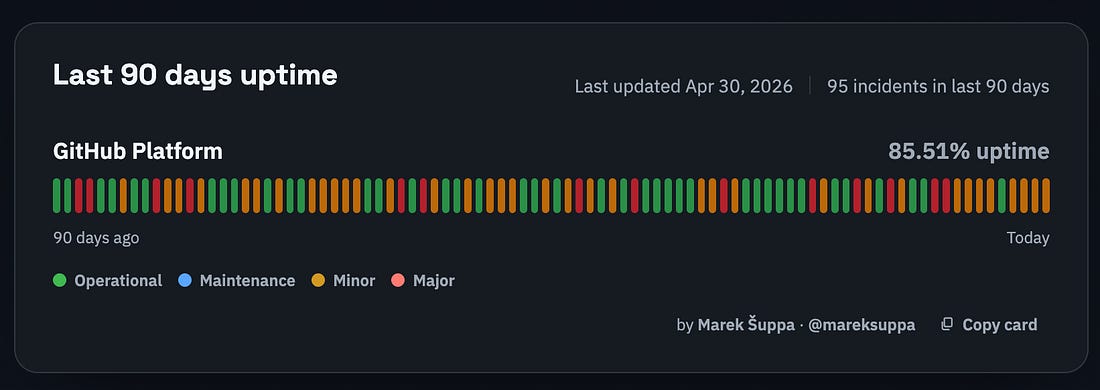
Mitchell’s experience suggests that GitHub’s official status page is inaccurate from the point of view of a heavy user like himself. The third-party “missing GitHub status page” is likely to be a better estimation: where GitHub’s reliability is at zero nines: at 85.51% uptime. That means that a part of GitHub was down for 2-3 hours, per day, on average, for the last 90 days (!!)
Mitchell’s complaint sounds straightforward:
CTO blames AI agent-fuelled load spikeGitHub CTO, Vlad Fedorov, shared an update on why reliability has been terrible for months at GitHub. He identified the load from agents being much bigger than expected as the culprit. Charts illustrating this were shared by GitHub:
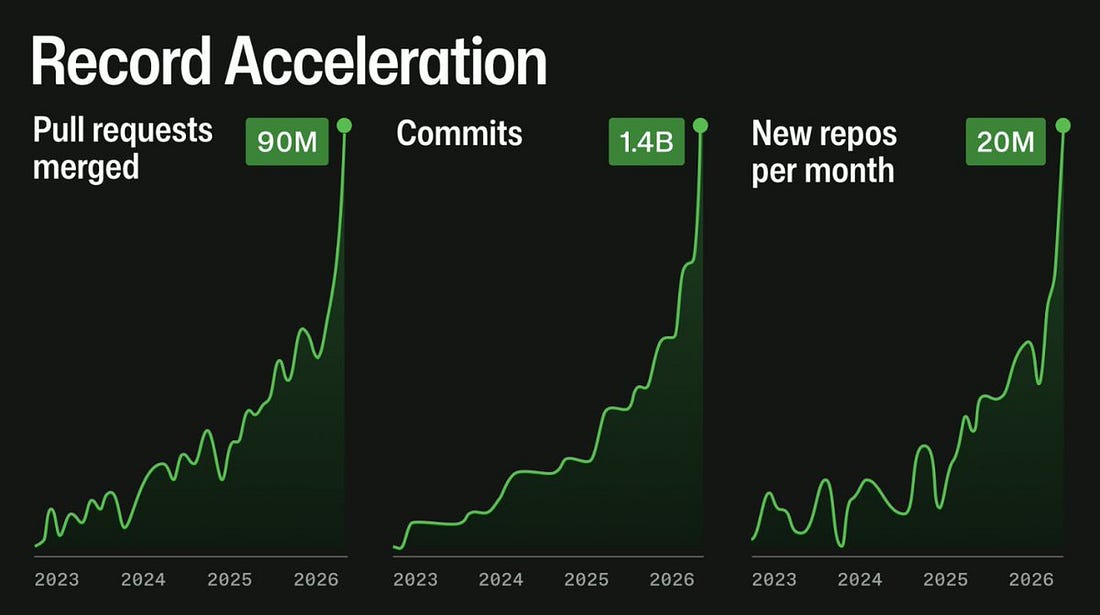
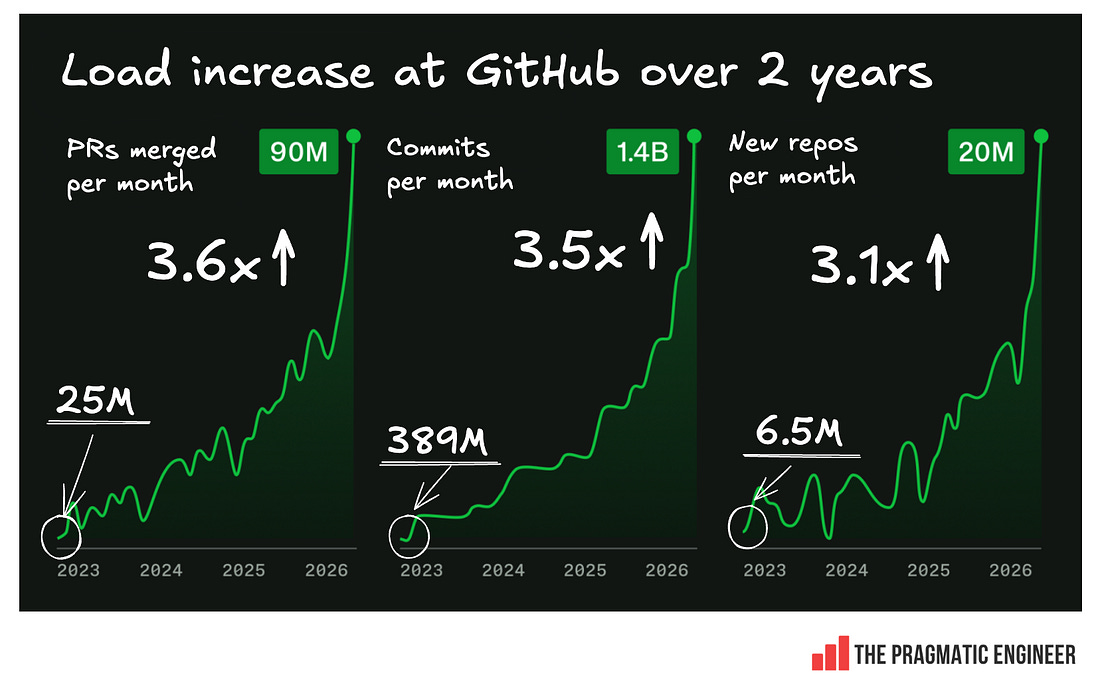
This chart looks eye-catching – but there’s just one tiny issue: no Y axis! So, while it tells the story of the load going up slowly and then very fast, we’re not told by how much. However, I managed to get data from GitHub, and below is the chart showing the actual load increase over two years:
A load increase of ~3.5x, spread across two years, doesn’t seem so brutal at first glance. It is nothing like a load increase of 10x in a month, and a good chunk of it occurred in recent months. So, why can’t GitHub handle it? In a blog post, Fedorov said:
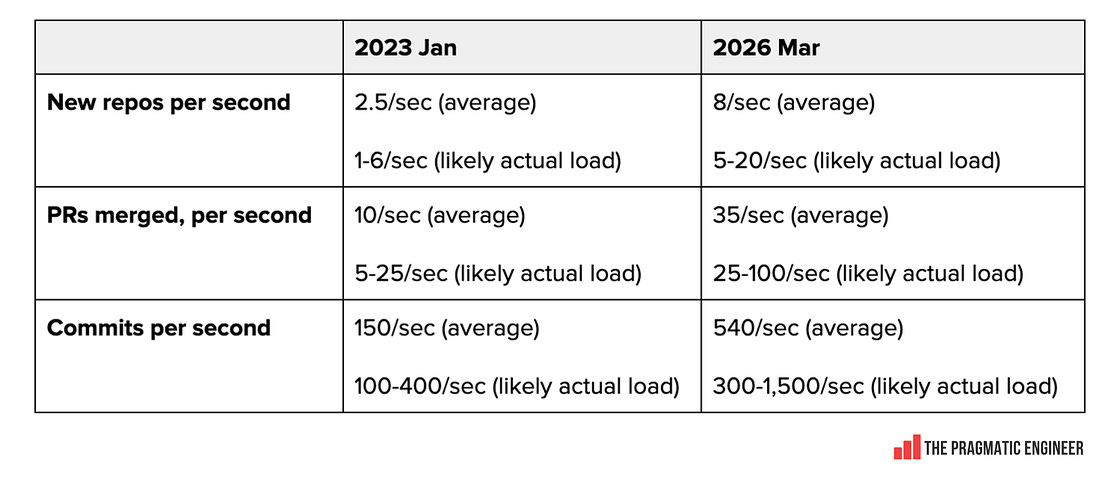
Here’s how the per-second load numbers from January 2023 and today compare:
GitHub took 15 years to achieve the 2023 numbers, and maybe it expected to continue growing in a comparable way in the future. If so, some engineering decisions about long-term infrastructure improvements would have been made obsolete by the arrival of AI agents. To add to GitHub’s challenges, the company is in the midst of a migration from its own data centers → Azure. In October last year, GitHub started to move over to Azure – a project expected to take 12 months – because it already had constraints on its own data center capacity. Such large-scale infrastructure migrations are hard enough when the load on a service is relatively stable; just making sure nothing breaks takes a lot of effort. But moving at a time when load is spiking means that bugs can cause more visible outages. Of course, GitHub can secure a lot more compute capacity on Azure, now they know what to expect. But other major companies prepared for a 10x increase in infra load, so why not Microsoft / GitHub? A year ago, I did research on how Big Tech was preparing to respond to the impact of AI on their business. Google was improving its internal systems to accommodate for a 10x increase in load. As we covered in The Pragmatic Engineer, in July last year:
Predicted enormous load increases were not secret knowledge within the industry, yet it seems GitHub was blissfully ignorant of their potential size. According to Vlad, GitHub did eventually plan for a need to increase capacity by 10x, but this was in October 2025, months later. In February 2026, the company is now adjusting that expectation to 30x. He wrote:
There’s also the question of whether GitHub miscalculated how much time it had to prepare for explosive load growth, and whether it was caught off guard when that growth materialized months sooner than expected at the start of this year. Given GitHub only started to prepare for a major load increase in October, its current problems are unsurprising. At the scale of GitHub, it’s common enough for each team owning a service to plan a year ahead on how much load their service will have, and hardware resources like storage, VMs, and networking are allocated accordingly. Load planning can account for up to half of the preparations, and when reality doesn’t conform to plans, some systems can struggle to scale up. So, on one hand, dealing with a 3.5x increase in load over 2 years should not be such a big deal for most services; especially not ones which can be horizontally scaled (when there’s not much state, and scaling is achieved simply by adding new nodes.) But GitHub probably stores a lot more state with pull requests, workflows, projects, etc. This probably makes scaling more tricky when it comes to databases and systems running workflows. GitHub also has 18 years of tech debt on its hands, and thousands of staff to align as “organizational overhead.” As its service load grows faster than before, responding is harder due to all that accumulated “debt”:
GitHub finds itself in the ‘innovator’s dilemma’: the company became successful because it built developer workflows that made sense, pre-AI, and it used to be able to accurately forecast service load changes. But now that engineering teams’ workflows include AI agents, GitHub’s own workflows are not necessarily the best fit, and the company failed to forecast service-level changes. Other vendors floored by AI load? Not reallyOne thing that doesn’t add up about the situation is that other vendors who are presumably experiencing similar load spikes don’t appear to be suffering with reliability issues as much. Vercel, Linear, Resend, Railway, Sentry, and other infra providers see record-level growth thanks to AI, but keep up with the load. Yes, it’s true that AI vendors like Anthropic, OpenAI, and Cursor have some reliability issues, but it’s not at the scale of GitHub’s. GitHub’s direct competitors, GitLab and Bitbucket, presumably see load going up similarly, but they’re not going down as much. An obvious question is how much of GitHub’s pain is self-inflicted? With Microsoft as owner, it has more resources at its disposal than any competitor or startup, and yet failed to predict load increases and is too big to respond with the nimbleness of a startup. It’s undeniable that solving for a major load increase is a hard challenge; it’s when the difference between average and standout engineering teams is apparent. GitHub hasn’t been responding like a world-class engineering org. GitHub alternatives?Every regular user of GitHub feels the pain of ongoing outages. As a dev, you can either hope Microsoft will eventually improve reliability, or seek alternatives. As covered above, Mitchell has chosen to quit and is currently deciding where to take Ghostty. The obvious alternatives are GitHub’s biggest competitors, GitLab, and Bitbucket. Each offers Git hosting, and neither comes with the uptime woes that GitHub is suffering from. Self-hosted solutions are also an option, like self-hosting your git repo, or going with a self-hosted forge like Forgejo, which is an open source, local-first GitHub alternative. I also suspect that, soon enough, we’ll see startups offering GitHub-like code hosting capabilities, while offering more robust uptime and being architected to handle the 30x-or-more scale which GitHub hopes one day to support. Read the full issue of last week’s The Pulse, or check out this week’s The Pulse. This week’s issue covers:
You’re on the free list for The Pragmatic Engineer. For the full experience, become a paying subscriber. Many readers expense this newsletter within their company’s training/learning/development budget. If you have such a budget, here’s an email you could send to your manager. This post is public, so feel free to share and forward it. If you enjoyed this post, you might enjoy my book, The Software Engineer's Guidebook: navigating senior, tech lead, staff and principal positions at tech companies and startups.
|




Comments
Post a Comment